
Logical Clocks and Clock Synchronization in Distributed Systems
Why Clock Synchronization is Hard in Distributed Systems?
As software engineers, when building products using state-of-the-art cloud technologies such as message brokers, queues, etc., we often overlook a very simple aspect of these large-scale systems spread across multiple machines. A concept that prevents unpredicted outcomes from happening — Clock Synchronization (aka. Time).
In simple terms, clock synchronization ensures that the clocks of all the entities constituting a distributed system align closely, allowing to correctly predict the order of the occurrence of the events for the coordination across different processes in the system. But practically, that’s not the case.
Why Clock Synchronization is Hard?
Clocks on different nodes can be built differently. Some may be using quartz crystal while others may be utilizing atomic vibrations (atomic clocks) to measure time. Over time these clocks can start drifting apart due to variations in their counting rates resulting in clock drift. For example, quartz clocks are susceptible to environmental factors such as temperature changes, which impact their correctness.
While one may argue that atomic clocks are more accurate and less susceptible to environmental effects than quartz clocks, there is still a high chance that the clock drift will be present in a system of multiple nodes each with a different clock type.
This scenario of not having a 100% correct sense of physical time on each node of the system, makes clock synchronization hard.

Partial Ordering with Logical Clocks
Although using physical clocks to timestamp the data packets in a distributed system may be prone to clock synchronization issues, the initial notion of physical time — an event A happened before an event B if A occurred at an earlier time than B, can still be preserved using logical clocks.
In simple words, if there never existed physical time, then we would still be able to assign chronological order to certain events. For eg. if person A is older than person B, it can be concluded that person A was born before person B. Similarly in a distributed system if a read returns data from a DB, then the create/insert data event must have happened before the read event (assuming the DB was empty initially). Despite not having physical timestamps, these operations can still be chronologically ordered.
Just like the examples above, if we can align on a way to define that an event A “happened before” an event B, without using a physical clock then we can find the correct ordering of the events by the notion of causality.
Mathematically speaking,
if A and B are events in the same process and A occurs before B, then A —> B, where “—>” denotes “happens before”,
if A is the sending of a message by one process and B is the receipt of the same message by another process, then A —> B,
if A —> B and B —> C, then A —> C

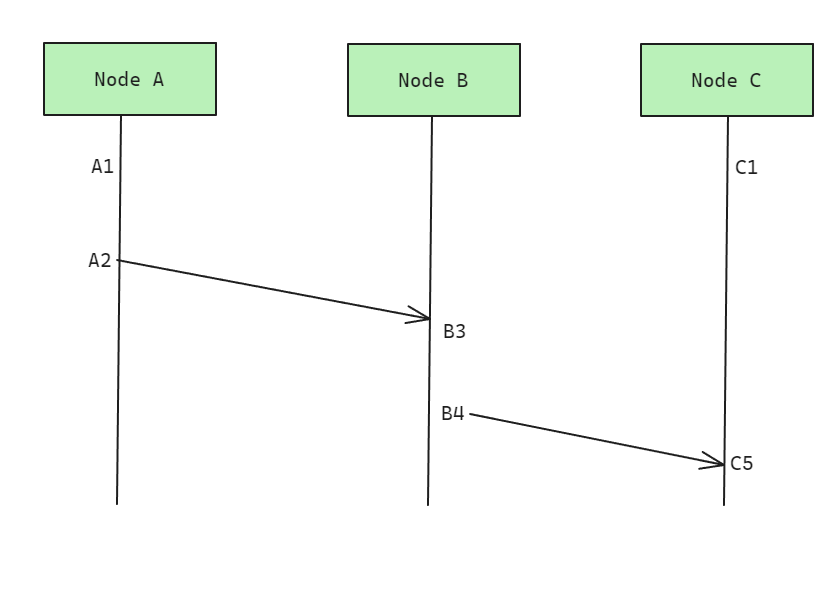
A simple logical clock (a counter) which is incremented before any operation/event. In this figure, A1 → A2 →B3 →B4 → C5

However, there will always be some events that are not related and hence can’t satisfy the notion of causality. These so-called concurrent events will impede achieving total ordering in a system. Therefore, only partial ordering of the events can be achieved using logical clocks.
References
L. Lamport and Massachusetts Computer Associates, Inc., “Time, clocks, and the ordering of events in a distributed system,” journal-article, 1978. [Online]. Available: https://lamport.azurewebsites.net/pubs/time-clocks.pdf