
How Bloom Filters Make Checking Millions of Usernames Lightning Fast
Understanding the Use and Working of Bloom Filters
What is a Bloom Filter?
We often encounter scenarios where we need to run look-ups in a large dataset but are only interested in whether a particular item exists in the set. Bloom Filter is a probabilistic data structure that allows us to do so space-efficiently.
Bloom Filter returns False: Item doesn’t exist in the set
Bloom Filter returns True: Item may or may not exist in the set. (We will look at the reason for that in a moment)
This means that when a Bloom Filter returns false, an item is guaranteed to NOT exist in the given set.

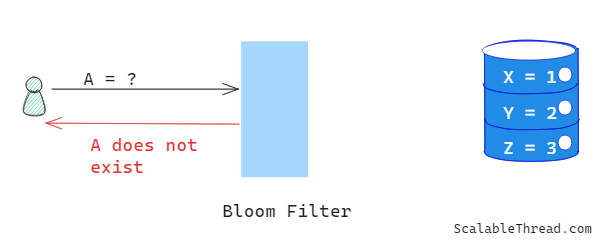

This makes Bloom Filter an ideal choice in scenarios such as determining whether a username exists in the data store. If it returns false for a given username, it is guaranteed that the username doesn’t exist in the data store, eliminating the need to scan the entire data store for such lookups.
How Bloom Filter Works?
A Bloom Filter comprises two main components: a set of hash functions and a bit array, which stores bits all initially set to 0.

Addition of Data
To add data to a Bloom Filter,
Hash the given value using all the hash functions, and then modulo each generated hashed value by the size of the bit array. This will return indices of the bit array.
For each index returned in the previous step, update the bit array value from 0 to 1 for each index. If the value is already 1, don’t update it.
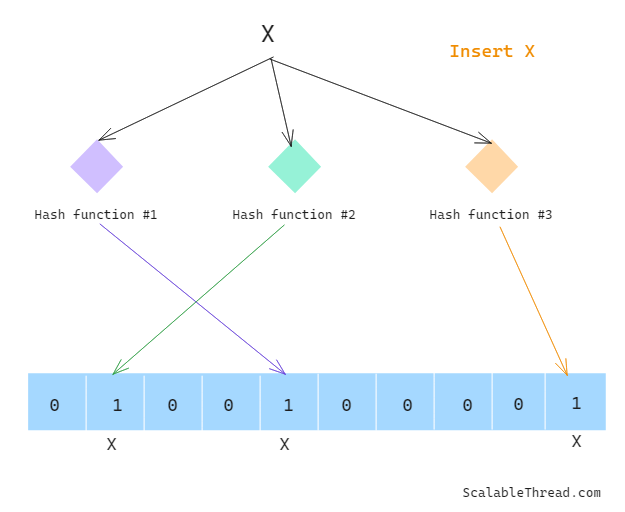

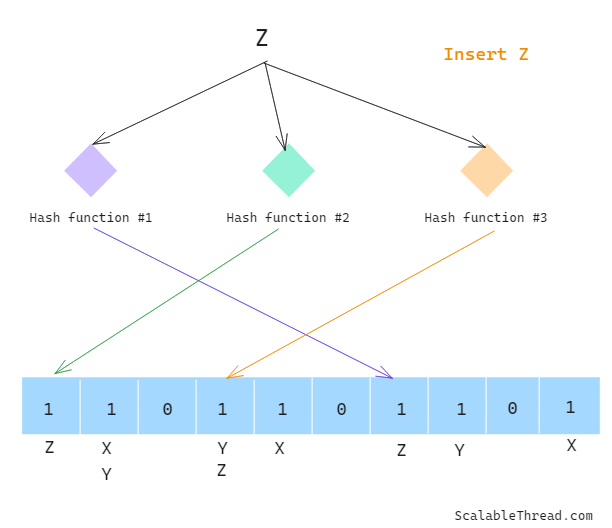
Checking If Data Exists
To check if a given value exists in a Bloom Filter,
Hash the given value using all the hash functions, and then modulo each generated hashed value by the size of the bit array. This will return indices of the bit array.
Get the values in the bit array at each of the above indices. If all values are 1, Bloom Filter returns true; if any of the values is 0, it will return false.


What About Collisions?
Since the hashed values are mapped to a limited-sized bit array, there is a high chance that two or more values return the same list of indices to be updated when added to a Bloom Filter, resulting in collisions. This is, in fact, the reason why a Bloom Filter can only guarantee if an item doesn’t exist as one of the indices in that case will be 0.
However, when all indices for a given value map to 1, it is impossible to tell if the indices were updated by the given value or some other value, as collisions can result in two or more values updating the same indices. This is why an item may or may not exist in the given set when it returns true.
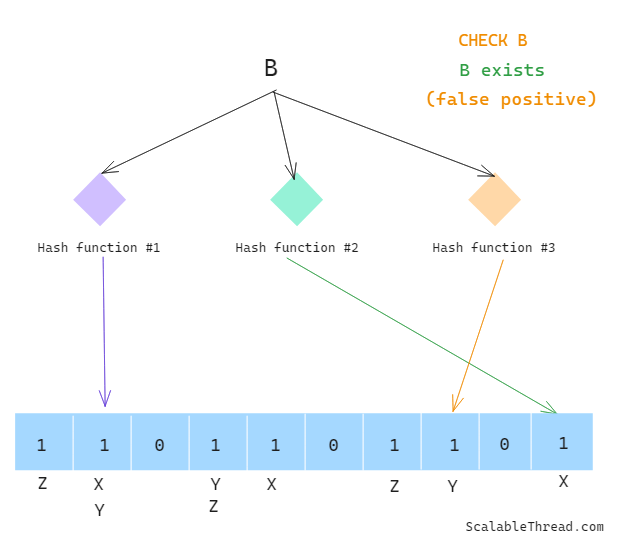
Why No Deletion?
As we noticed in the previous section, it is impossible to tell if the indices were updated by the given value or some other value; it’s impossible to run deletions in a Bloom Filter. A deletion would mean setting all the indices for a given value to 0, which can also result in the deletion of some other value, as two or more values can map to the same set of indices. This will eventually lead to scenarios where a Bloom Filter returns false for an item that exists in the data store (false negative).

Production Fun Fact!
Google’s Big Table uses Bloom Filters to reduce the number of disk accesses.
Databases (such as Cassandra, etc.) using LSM Trees use Bloom Filters to run quick look-ups on SSTs.
References
CMSC 420: Bloom Filters. (n.d.-a). https://www.math.umd.edu/~immortal/CMSC420/notes/bloomfilters.pdf
Wikipedia contributors. (2024, August 12). Bloom filter. Wikipedia. https://en.wikipedia.org/wiki/Bloom_filter
CMSC 420: Bloom Filters. (n.d.-a). https://www.math.umd.edu/~immortal/CMSC420/notes/bloomfilters.pdf