
How Consistent Hashing Minimizes Data Movement in Scalable Systems
Understanding Consistent Hashing in Distributed Caches
What is a Distributed Cache?
Caching data helps improve overall performance in any system. In a single-node cache state store system, getting or setting the cache values requires calling the GET or SET APIs.

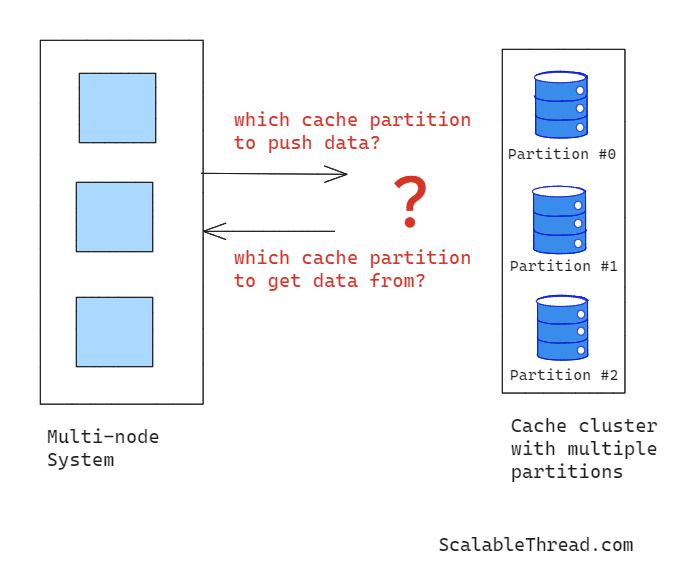
As the system grows, the cache size needed also increases, which requires upscaling the cache. After a certain point, vertical scaling of the cache isn’t an optimal solution, and just like any other state store, the cache also needs to be horizontally scaled by splitting it into multiple partitions, creating a distributed cache. At this point, the APIs from the cache can’t be used directly because the client needs to know which partition the required data resides in or which partition the data should be pushed to.
Hashing Input to Find Partition
To solve this problem, the client utilizes a hash function, which takes the key of the data to be cached as the input and produces a positive integer as an output. Once the key is hashed, the client performs a modulo operation with the number of partitions in the distributed cache on this positive integer. The resultant value indicates the partition index where the data is in the distributed cache.
For instance, if there are 3 partitions and H(K) = 100, where H represents the hash function, and K is the data key, applying the modulo operation gives us 100 % 3 = 1. This value represents the partition index where the data associated with the key K will be stored.

What If a Server Goes Down or a New One is Added?
Let’s say in the above example, one of the three cache partitions goes down, leaving us with two partitions. This means the data key K will reside in partition 0 (100 % 2 = 0). Since the approach to finding the correct partition depends on the total number of cache partitions in the system, any change in the total number of partitions will result in a cache miss for most of the keys. This will require all the data in the cache to be rehashed and reallocated to the remaining two partitions, which is not an optimal approach. A similar scenario will happen if a new partition is added to the system.

What is Consistent Hashing?
Consistent hashing is a technique for finding the index of a partition in a distributed cache regardless of the number of partitions in the system. Each partition is assigned a position on a ring, which is essentially a circle. The hash function employed in this method produces an output range from 0 to 360 degrees, representing a position anywhere on the edge of the ring.
The hash value of the data key on the ring, denoted as H(K), is calculated to determine the partition index for a given key K. The next partition in either the clockwise or counterclockwise direction on the ring (depending on the convention agreed upon at the start) is assigned as the partition for the key K.

Solving the Server Scaling Problem
When a partition is removed from the ring, only the keys cached on the retired partition need to be reallocated to the next partition on the ring. All the data on the remaining partitions remains unaffected.
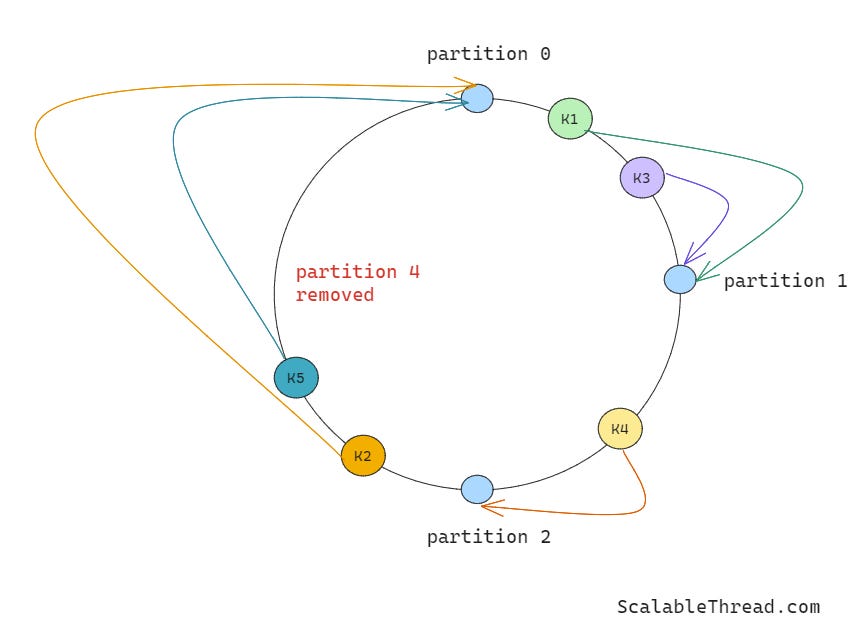
Similarly, when a new partition is added to the ring, it is populated using the above approach, and only the data hashed to the left of the new partition (clockwise direction), which was previously allocated to the partition next to the latest partition, is affected.

Production Fun Fact!
Slack utilizes consistent hashing for its channel servers, which are stateful, in-memory nodes that store the history of channels. Each channel server is assigned to a specific set of channels using consistent hashing. This approach enables Slack to increase or decrease the number of channel servers without reorganizing all the data stored on them.
References
Thangudu, S. (2023, April 11). Real-time messaging. Slack Engineering. https://slack.engineering/real-time-messaging/
Introduction and consistent hashing. (n.d.). https://web.stanford.edu/class/cs168/l/l1.pdf