
How Databases Avoid Data Loss with Write-Ahead Logs
Understanding Database Failure Handling Using Write-Ahead Logs
Failure is one system attribute guaranteed to happen irrespective of how well a system is designed. Databases are no exception! A database restarting after a crash or a failure should return to its state just before crashing. Besides failure handling, the distributed databases with multiple replicas must maintain high performance and low latency. This is accomplished through a technique known as Write-Ahead Logs (WAL).
What are Write-Ahead Logs?
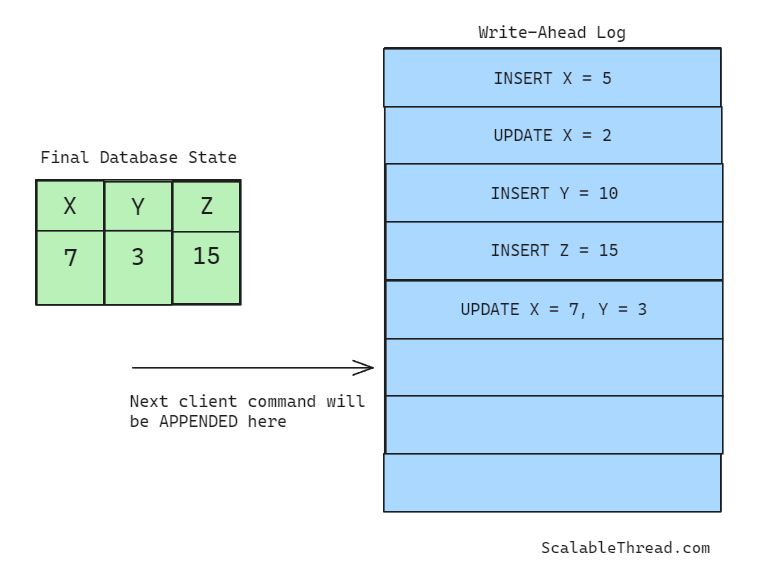
Each node in a database system keeps an append-only log file in persistent storage and every client update sent to the node is first appended to this file (write-ahead) and later applied to the data in the database. This logging technique is called Write-Ahead Logging because the update commands are written to the logs before the actual updates on the data are performed.

WAL doesn’t hold the actual state of the data held in the database, but instead, each log entry is a copy of the client’s query or command sent to the database. Once a query is written to the log file, it is executed on the data stored in the database.
How does WAL Help Prevent Data Loss?
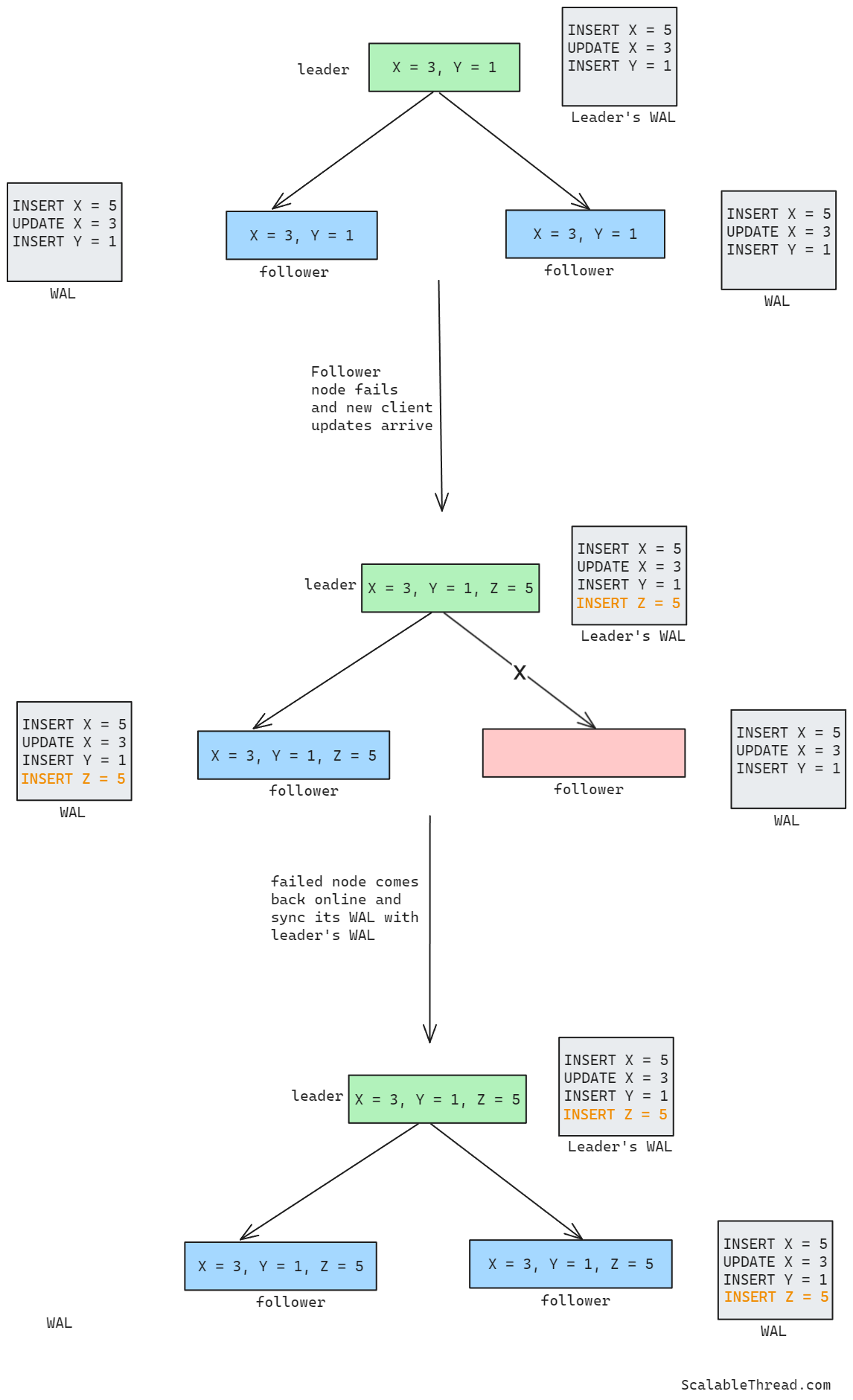
Write-ahead logs are written on a persistent storage (a disk) which allows them to survive a node failure. In a distributed database, once a follower node restarts after a failure, it reads its WAL file from the start and executes updates in the log file sequentially. This allows the node to return to its state before the failure. Think of it as how a bank statement lists the credit or debit transactions. If those transactions are run one by one on the initial balance, the final balance of the account can be calculated.
Once the follower node has reconstructed the data state, it synchronizes its WAL with the leader node’s WAL by requesting all the client updates that happened while the node was in the failed state. After the leader node shares all the client updates, the follower node updates its WAL and executes all updates on the data to bring the data state consistent with the leader node and other follower nodes.
There can be a scenario when there are millions of entries in the WAL which can impact the restart time of a node. This is addressed by taking snapshots of the database at regular intervals. On restart after a failure, only the WAL entries that were appended after the last snapshot are executed. This greatly reduces the number of WAL entries that need to be executed to reconstruct the prior state of the database and hence improves the performance.