
How Distributed Systems Avoid Race Conditions using Pessimistic Locking
Understanding Pessimistic Locks, Leases, and Fence Tokens in Distributed Systems
What is Pessimistic Locking?
When two updates to a data source are executed in a single-process system, they are always run one after the other, as the process will only be working on one update at a particular time. However, in a multi-process system, there is a chance that the two updates can be executed at the same time by the processes on the shared data source. This situation is known as a race condition, and it can lead to an undesired data state.
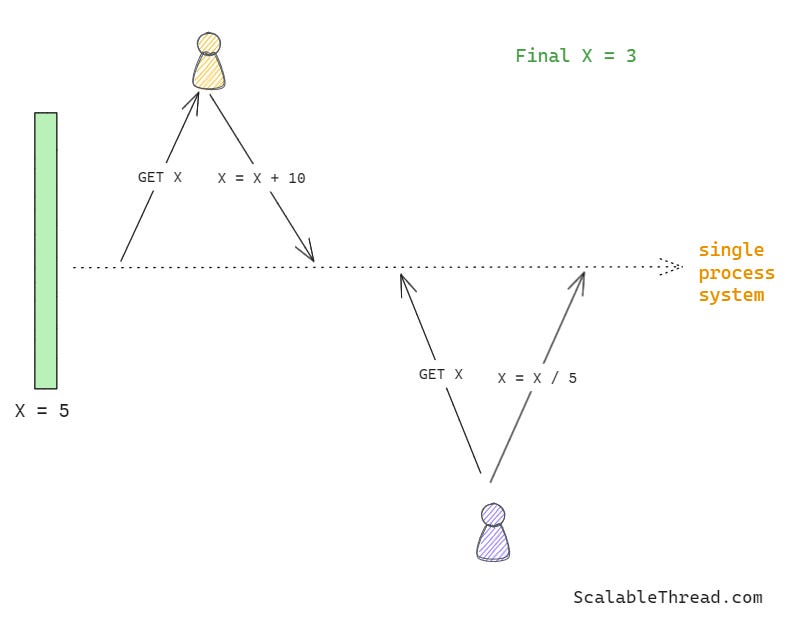

To avoid this race condition and ensure correctness while writing data updates to a shared data resource, one process must ensure that no other process can access the data while it pushes updates. To achieve this, the process writing updates acquires a lock on the data source and releases it once it has completed updates. No other process can access the data while a lock has been placed on it. This type of locking is called pessimistic locking, where access to the shared resource is blocked before updating it.

Pessimistic Locking in Distributed Systems
On a high level, locking in distributed systems works very similarly to a multi-process system described above; however, the inherent issues of a distributed system, such as node failures or replacements, network partitions, etc., make it more complex.
In distributed systems, information about who owns which lock on what resource is held in a cluster-wide lock database. This database is updated whenever a node acquires or releases a lock on a shared resource.
Just Acquiring a Lock is Not Enough — Lease it!
Consider a scenario where a node acquires a lock and freezes or fails before releasing it. In this case, the node still holds the lock when viewed by the rest of the system, as the node did not update the release information in the lock database/service.
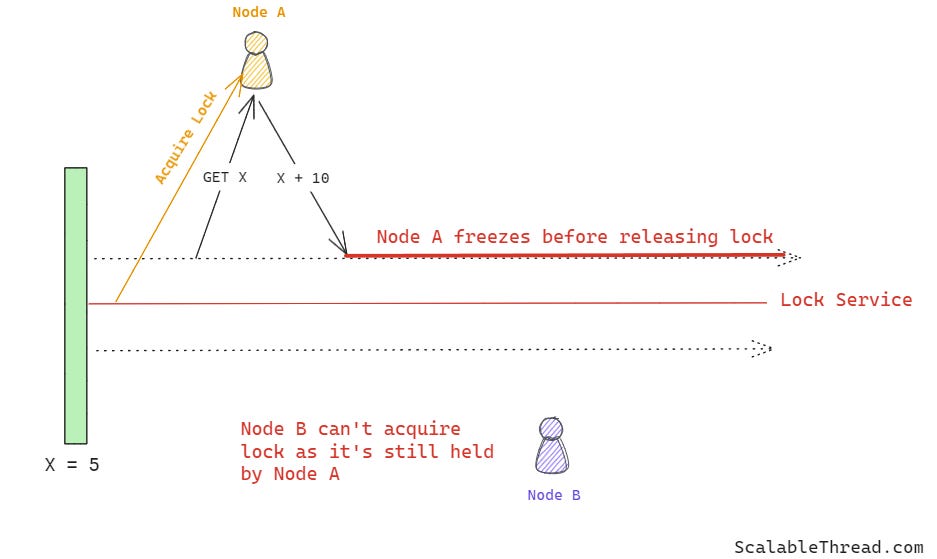
To address this issue, every time a node acquires a lock, a time to live (TTL), also known as a lease for the lock, is set in the lock database record. Once the lease expires, the lock on the shared resource is released, irrespective of whether the node that initially acquired the lock has completed its updates. This allows the system to handle the scenarios where a node fails to release the lock due to any failure.

Node Didn’t Fail But Paused and Then Resumed — Stale Updates!
Alright! Now that we have a lock with a lease, let’s imagine a scenario where a node, say node A, acquires a lock with a lease and then pauses or freezes for any reason before updating the shared resource. During this freeze period, the lease expires, and the lock is now released for the rest of the system. Another node, say node B, acquires this lock on the shared resource and updates its value. When node B updates the resource, node A resumes, thinking it still owns the lock, and pushes the updates to the resource, overwriting node B’s updates. This brings the shared data resource to an incorrect state.
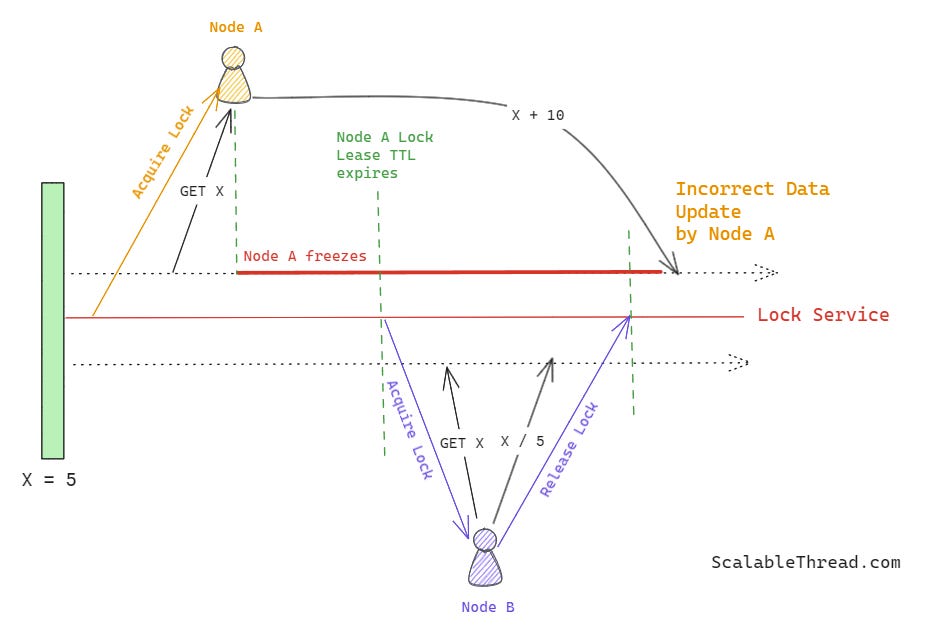
Fence Tokens!
To address this issue, each node in the system must send a new fencing token along with each write request to the shared data resource. The shared data resource will reject an older fencing token if it has already seen a newer one. For simplicity, this fencing token can be a number that the lock database increments every time a lock is requested on the shared resource.
In our previous scenario, when node A acquired the lock, it was assigned a fencing token value of 10, and when node B acquired the lock after node A froze, it was provided a fencing token value of 11. Since node B has executed its updates, the shared data resource has already seen a fence token value of 11. So, it will reject the updates sent by node A after it resumes because node A’s fence token is smaller than that of node B (which acquired the lock after node A).

References
How to do distributed locking — Martin Kleppmann’s blog. (2016, February 8). https://martin.kleppmann.com/2016/02/08/how-to-do-distributed-locking.html
Isn't this the principle behind using HTTP ETags when updating a resource?
In the case of inconsistency the webserver returns 412 Precondition Failed on PUT/PATCH requests.
For someone to read, You can check this blog as well
http://antirez.com/news/101