
How Failover Works in Single Leader Databases
Strategies for Handling Failover in Single Leader Architectures
What is Single Leader System?
In a single-leader system, one node (the leader) handles all write operations. Followers replicate the leader’s data and serve read requests to distribute the load. The request is sent only to the leader when a client wants to write data. The leader processes the write, records it in its local log (a sequence of operations), and then sends this update to all its followers. Followers apply the updates in the same order as the leader, ensuring they eventually have the same data.
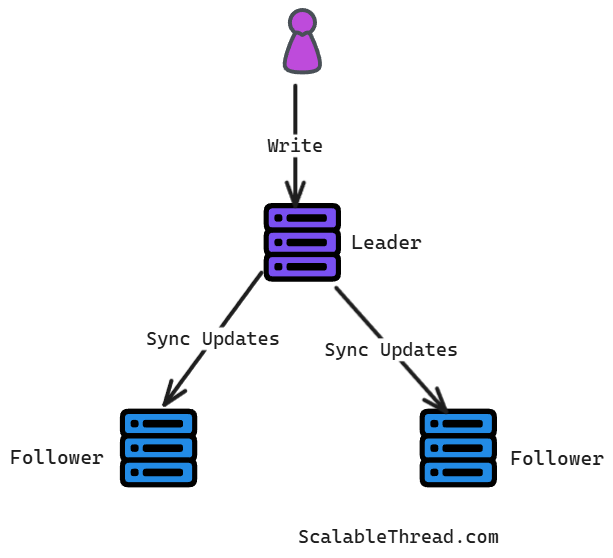
What is Failover?
Failover is the process of automatically switching to a backup system or node when the primary system or node fails or needs to be taken offline for maintenance. In single-leader systems, failover deals with two main scenarios: a follower node failing or the leader node failing. The goal is to minimize downtime and data loss.

Follower Failover
The followers are read-only replicas (or read-mostly) that do not accept direct writes from clients. However, their failure does not stop the system from accepting new data.
Detection: The leader or a monitoring system detects unresponsive followers (e.g., through missed heartbeats or failed connection attempts).
Removal: The failed follower might be temporarily or permanently removed from the list of active followers. Read requests previously directed to it need to be rerouted to other followers or the leader.
Replacement: A new follower node can be started. This new node needs to catch up with the leader's current state. It typically does this by copying a recent snapshot of the leader's data and then applying all the changes from the leader's log that occurred after the snapshot was taken. Once caught up, it starts receiving live updates like any other follower.

For example, if a follower crashes, a new virtual machine can be provisioned, installed with the necessary software, and configured to connect to the leader to start replication from the last known point or a full snapshot. Follower failover is relatively straightforward because the leader remains operational throughout the process. However, delays in detecting failures or slow synchronization can temporarily reduce redundancy, making the system more vulnerable.
Leader Failover
Leader failure is more critical because the leader is the only node that can accept writes. Without a leader, the system cannot process new data updates.
Detection: The first step is detecting that the leader has failed. This is done through health checks or heartbeats monitored by followers or an external coordination service. If the leader doesn't respond for a specific period, it's considered failed.
Leader Election: Once the failure is confirmed, the system must choose a new leader from the available followers. The most common requirement is to select the follower with the most up-to-date data log. This minimizes potential data loss. Various algorithms exist for leader election, often managed by consensus protocols (like Raft or Paxos) implemented directly by the nodes or external services.
Reconfiguration: Clients and remaining followers must be informed about the new leader. Clients need to redirect their write requests to the newly elected leader. Followers need to disconnect from the old leader and follow the new one.
There are two main types of leader failover:
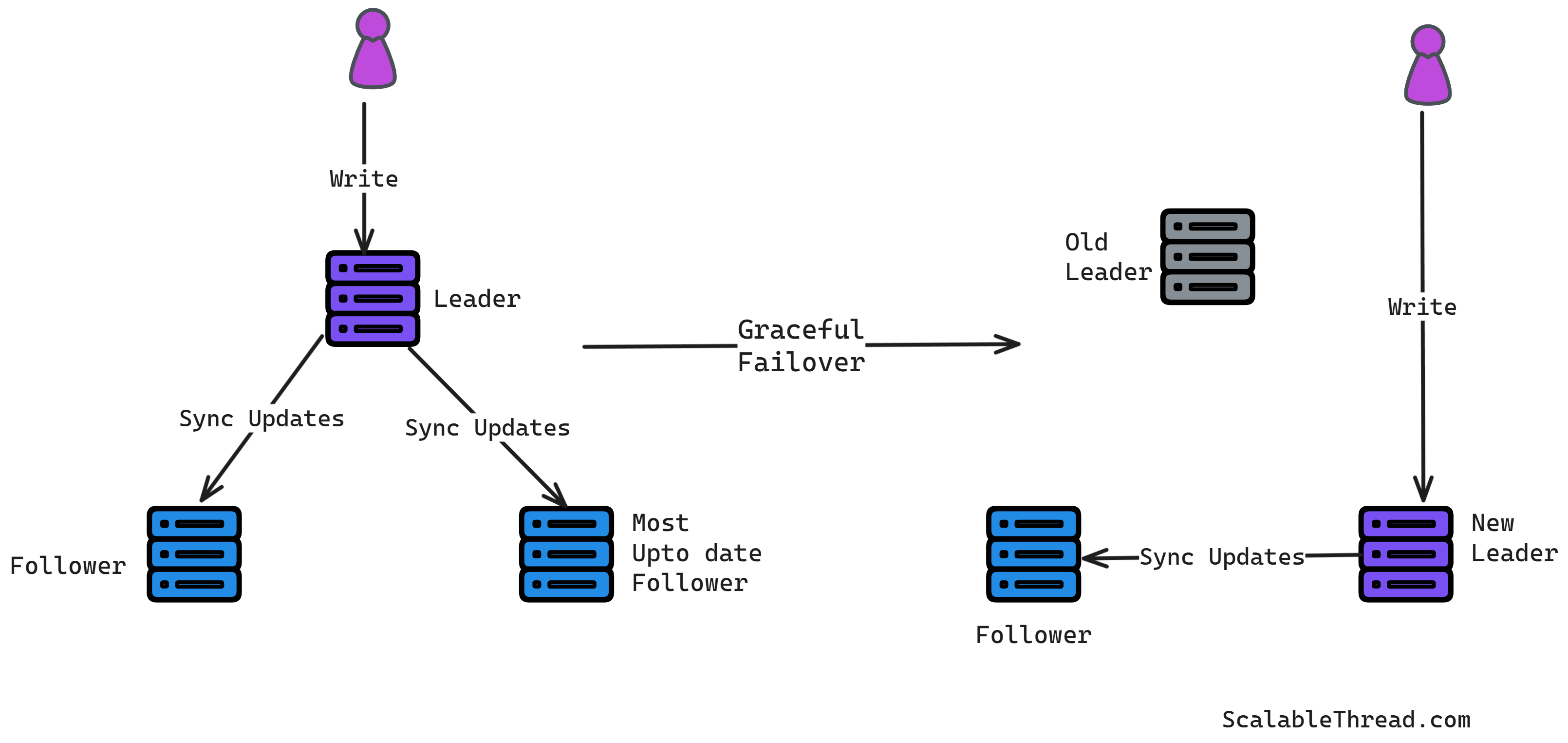
Graceful Failover (Planned)
This happens during scheduled maintenance or the leader's planned shutdown. The current leader finishes processing pending writes, ensures one specific follower is fully up-to-date, and then transfers leadership to that follower before shutting down. This process typically involves no data loss because the handover is controlled.
Emergency Failover (Unplanned)
This occurs when the leader fails unexpectedly (e.g., crashes, network partition). The system must react automatically. A follower node (usually the one with the most recent data log) is promoted to be the new leader through the election process. If it recovers later, the old leader might rejoin the cluster as a follower to avoid having two leaders.
Network latency matters when choosing a new leader, especially in geographically distributed systems. Ideally, the new leader should be located "close" (in terms of network latency) to most clients or the previous leader's location to minimize the time it takes for requests to travel. However, the primary concern is data consistency (choosing the most up-to-date follower), so proximity is a secondary factor.
If you enjoyed this article, please hit the ❤️ like button.
If you think someone else will benefit from this, then please 🔁 share this post.
I think linking to some consensus algorithm like Raft will be useful