


How GitHub Scaled Push Flow Using Apache Kafka to Handle Millions of Pushes
Understanding How GitHub Reliably Handles Half a Billion Pushes Every Month

What is Push Flow?
When a code change is pushed to GitHub, it updates the main branch and triggers events such as syncing changes to open pull requests (merge conflicts! Remember?), dispatching webhooks, starting GitHub workflows, publishing GitHub pages, etc. The process of completing these push-dependent tasks is termed Push Flow.
Old Architecture
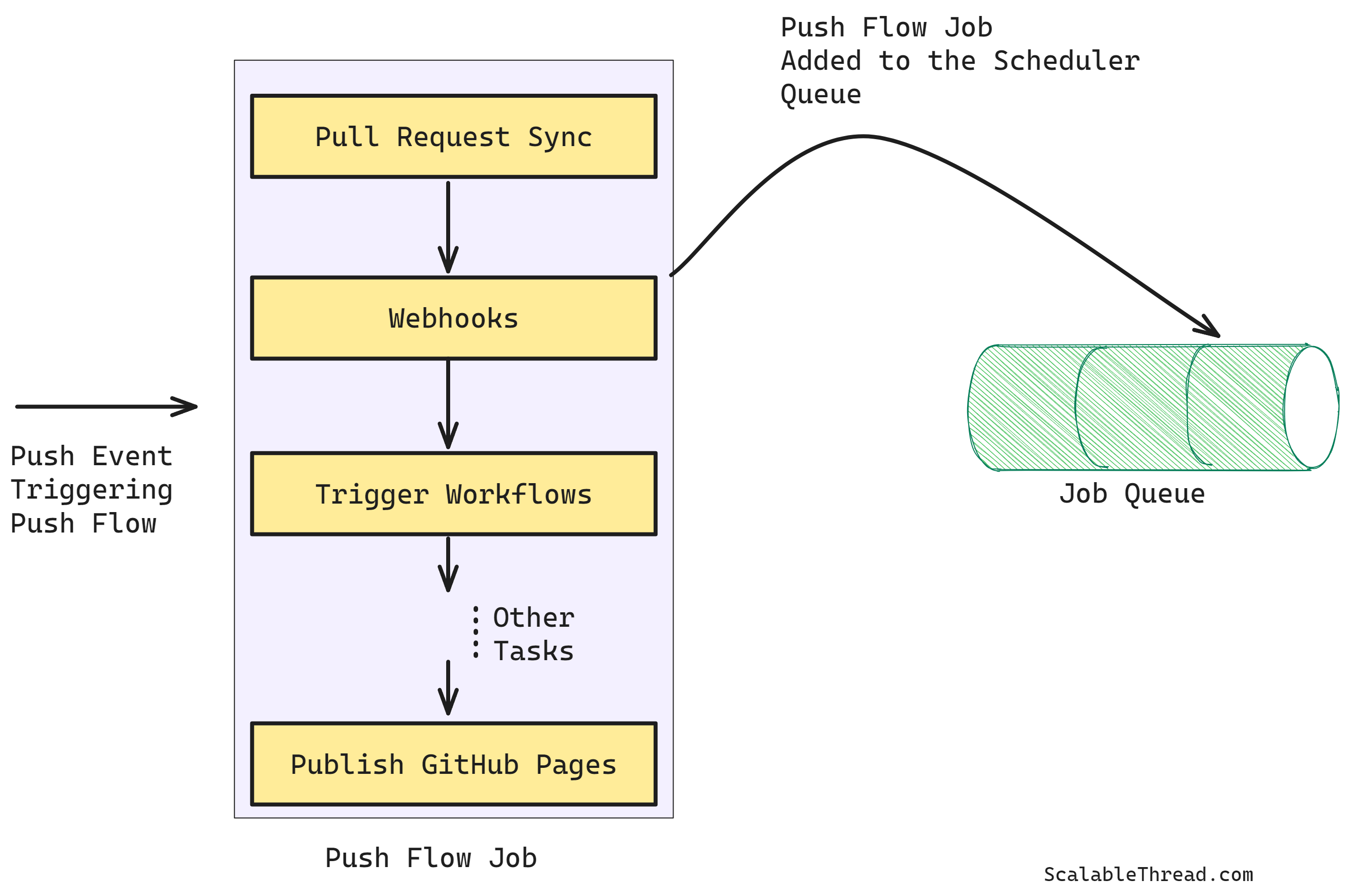
In old architecture, upon every push event, a background job to complete all the tasks of the push flow was triggered. This job completed all of the above functions sequentially, with each task depending on the successful completion of the previous task—failure to complete any task required restarting the entire job.
Problems
Retries were Difficult
Restarting the job after failure was difficult because, in scenarios such as webhooks, sending webhooks too late or multiple times is not desirable. To avoid such scenarios, the job was often not retried if it failed. This resulted in several crucial tasks not running if a task before them failed.Tight Coupling
The job's sequential nature resulted in tight coupling between different tasks, even if they were logically not dependent on each other. For example, any failures during the writes to the DB at the start of the job resulted in subsequent steps not running even though some subsequent steps were not dependent on the data in the DB.High Latency
As expected, running one task after completing the previous task adds to the overall latency of the crucial functions.
New Architecture
The new architecture broke down the sequential push flow process and decoupled the job tasks into individual processes. These decoupled tasks were grouped based on logical relationships such as order dependency, retry ability, etc. Each group of tasks was assigned its own background job and retry configuration. To asynchronously trigger these jobs through the pub-sub pattern, a Kafka topic was also set up where all GitHub push events are published. A Kafka event triggers each push flow job independently (pub-sub pattern).

How This Solved the Problems
Higher Decoupling
Keeping tasks in independent job groups eliminated the dependency amongst the functions that were not logically dependent. For example, steps not dependent on DB write run in a separate group, making them independent of DB failures.
Decoupling also allowed better ownership, as multiple teams can now independently own different parts of the push flow.
Task failure in one group will not impact tasks in the other groups.
Reduced Latency
Decoupling tasks also allowed independent tasks to run in parallel, reducing the push flow's overall latency.Improved Observability and Reliability
Dividing sequential flow into separate groups allows for more granular monitoring of different components and easy debugging in case things go wrong somewhere in the flow.
Having separate retry policies for each group also allows for easier retries, which makes the system more reliable
References
Haltom, W. (2024, July 23). How we improved push processing on GitHub - The GitHub Blog. The GitHub Blog. https://github.blog/engineering/architecture-optimization/how-we-improved-push-processing-on-github/