
How Grab Stores and Processes Millions of Orders Everyday
Understanding the Distributed Data Solution That Powers the Grab Orders Platform
Requirements
Grab’s order platform processes millions of GrabFood and GrabMart orders daily. To support this, Grab solves two scenarios — transactional queries and analytical queries.
Transaction Queries are critical to different ongoing order stages, from creation to completion. This includes queries to create an order, update an order, get an order by ID, or get all open orders by a customer ID. These queries are required to be strongly consistent.
Analytical Queries are useful for order statistical purposes and for retrieving past orders. This includes queries such as getting past orders with certain conditions or getting order statistics like the number of orders, etc. These queries provide data with eventual consistency.
Architecture
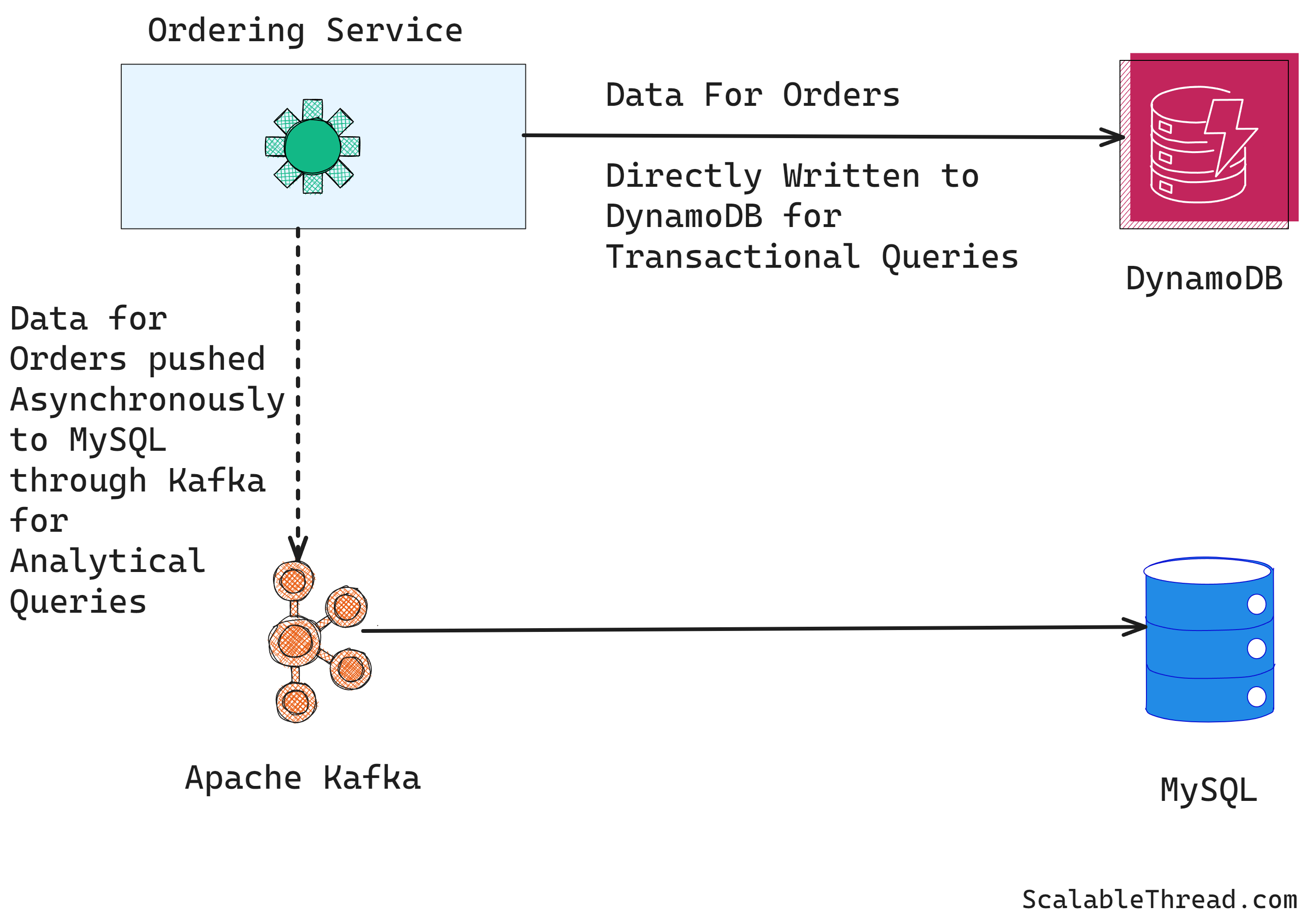
To solve the above requirements, Grab implemented two separate database solutions.
Transaction Queries
Grab chose DynamoDB for transactional queries because
it provides scalability and availability by partitioning the data and replicating the partitions.
it provides support for the strict consistency model
it can handle the hot-key problem by providing dedicated partitions to frequently accessed keys, which offers high availability for the system
The table containing order data is partitioned by orderId, which allows for easy get and update by orderId queries. To support batch queries like getting all orders by a user, Grab added a Global Secondary Index on userId. Since the transaction queries need to support only ongoing orders, once an order is completed, its GSI is deleted. This means that at any time, the GSI only holds index for ongoing orders. This keeps the index lean and provides better performance and low costs.
Analytical Queries
Grab opted for MySQL to provide support for analytical queries. The order data is partitioned by the creation time every month. This is because most of the data is accessed monthly, so partitioning the data by the creation time reduces cross-partition queries. Partitions older than six months are dropped at the beginning of each month to keep the database lean and performant. Besides this, MySQL allows for complex aggregations needed for analytics purposes.
Keeping Data in Transaction and Analytics Consistent
Grab built a data ingestion pipeline using Apache Kafka to push data to analytics DB asynchronously. This allows the analytics DB (MySQL) to become eventually consistent with transaction DB (DynamoDB) without adding extra latency to order service as the data is pushed to analytics asynchronously.

If the write fails on the producer side, the message is stored in the AWS SQS queue to be re-tried. If the retry fails, the message is stored in SQS’s dead letter queue to be retried later.
The data ingestion pipeline handles duplicate and out-of-order messages.
References
How we store and process millions of orders daily. (n.d.). Grab Tech. https://engineering.grab.com/how-we-store-millions-orders
Love MySQL, but for analytical queries and things-that-look-like-reports, wouldn't a system with more robust (or any) parallel query capability be a fit? IIRC, MySQL just does parallel query on WHERE-less select count(*) queries...