
How Indexes Work in Partitioned Databases
Understanding Local and Global Secondary Indexing for Large-Scale Systems
What is Partitioning?
Managing and efficiently querying vast amounts of data in distributed systems is a big challenge. Partitioning (or sharding) is a common technique to handle this scale. It involves splitting a large database into smaller, more manageable pieces called partitions. Each partition holds a portion of the data and can live on a separate machine in a cluster. For example, consider a customer database with millions of records. The system can distribute the load across multiple machines by partitioning the data based on a key such as CustomerID.
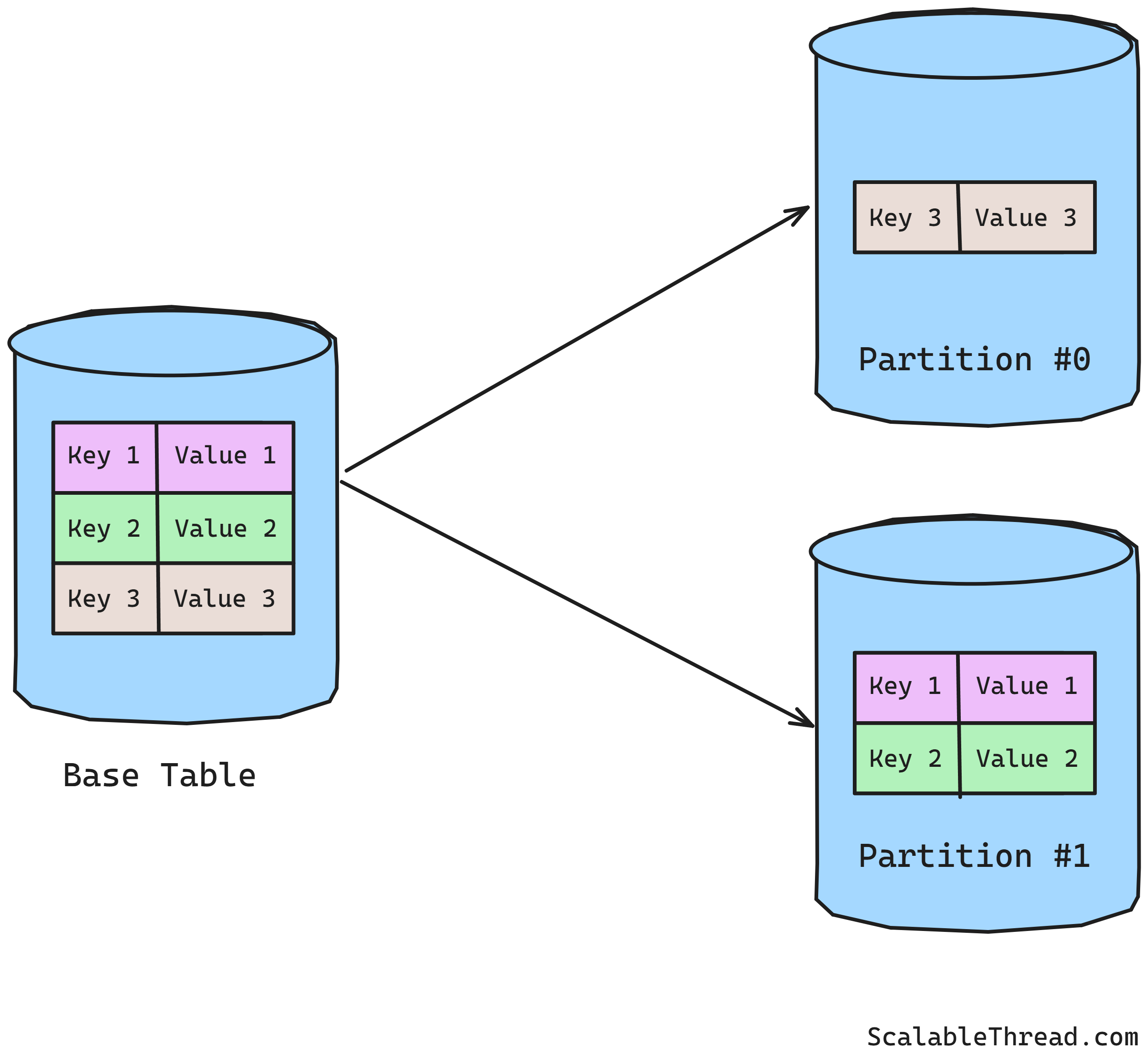
Each partition acts like a smaller, independent database. A primary index is maintained within each partition, typically based on the table's primary key. If the table's primary key is also the partition key, query filtering can be done as follows:
The query router (or client) determines the target partition using the partition key value provided in the query (e.g., by hashing it).
The query is sent only to that specific partition.
The target partition uses its local primary index to locate the data quickly.
For example, SELECT * FROM orders WHERE customer_id = 54321 AND order_id = 9876; If partitioning is by customer_id, the system hashes 54321 to find the correct partition. That partition then uses its local index (likely on (customer_id, order_id) or order_id to find the specific order.
Secondary Indexes
Often, applications need to query data based on attributes other than the partition key, such as searching orders by product_id. Performing such queries without an appropriate index would require scanning every row in every partition (a full table scan), which is infeasible in large systems. To support such queries, secondary indexes are created on these non-partition key columns. In partitioned databases, secondary indexes can be local (tied to one partition) or global (covering all partitions).
Local Secondary Indexes
A local secondary index exists within each data partition and only references data stored on that specific partition. For example, the orders table is partitioned by customer_id. A local secondary index is created on product_id. Partition 1's product_id index only contains entries for orders belonging to customers whose customer_id hashes to Partition 1.

Despite their benefits, local secondary indexes have limitations. Since they are confined to individual partitions, querying them requires the system to perform a "scatter and gather" operation. This means the query is broadcast to all partitions. Each partition independently searches its local secondary index for the matching data, and the query coordinator aggregates the results. While effective for small datasets, this approach becomes inefficient at scale because it increases network overhead and query latency.

Global Secondary Indexes
Distributed systems use global secondary indexes to overcome the limitations of local secondary indexes. A global secondary index spans all or multiple partitions and is not tied to the table's primary/partition key. It maps the secondary key value(s) directly to the base table's primary/partition key(s). Queries targeting the secondary key first consult the global index. The index returns the primary/partition key(s) of the matching rows. The system then uses these keys to query only the necessary data partitions directly.

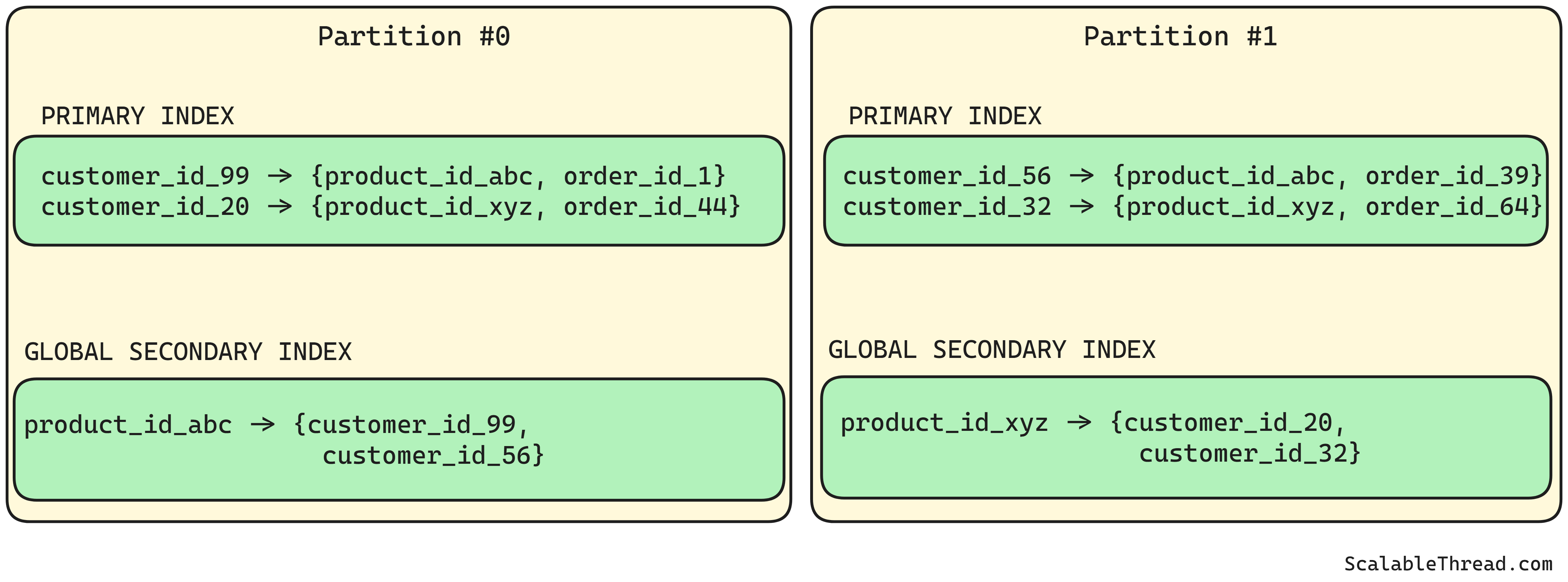
For example, the orders table is partitioned by customer_id. A global secondary index is created on product_id. This index stores entries like
product_id_abc => [(order_id_1, customer_id_99), (order_id_39, customer_id_56)]andproduct_id_xyz => [(order_id_44, customer_id_20), (order_id_64, customer_id_32)]
Query SELECT * FROM orders WHERE product_id = 'product_id_xyz' returns [(order_id_44, customer_id_20), (order_id_64, customer_id_32)] from the global secondary index and then uses the retrieved customer_id values (the partition key) to determine the specific data partitions holding the relevant rows. Queries (eg. SELECT * FROM orders WHERE customer_id = 'customer_id_32' AND order_id = 'order_id_64') are then sent directly to those partitions using the full primary key.
Problems with Keeping Global Index
Global secondary indexes solve the problem of scattering and gathering by centralizing the indexed data. However, maintaining a global index on a single machine poses challenges. The node can become the single point of failure or a bottleneck during index reads and updates. As the dataset grows, the index itself can become a bottleneck, leading to slower query performance and potential downtime.
Splitting Global Indexes Across Multiple Partitions
The index itself is partitioned across multiple nodes, similar to how the base data is partitioned, to address the scalability issues of global secondary indexes. The partition key for the global index is typically the indexed column itself. Each index partition holds a slice of the global index entries based on the index's partition key.
For example, the global index on product_id (shared previously) is partitioned across 2 nodes based on hash(product_id) % 2. A query for product_id = 'product_id_xyz' calculates hash('product_id_xyz') % 10, say it results in 1. The query is sent to Index Partition 1. Index Partition 1 returns the relevant (customer_id, order_id) pairs. Then, the system fetches the actual order data from the data partitions indicated by the customer_id values.
Updating Global Secondary Indexes
Updates to a partitioned global secondary index require coordination because multiple, potentially remote partitions must be updated atomically or consistently. Whenever a record is inserted, updated, or deleted, the corresponding entry in the global index must also be modified. This process involves two steps:
Primary Data Update: The system first updates the primary data in its partition.
Index Update: The system then propagates the change to the appropriate partition of the global secondary index.
To ensure consistency, distributed databases often use techniques such as eventual consistency or distributed transactions.
If you enjoyed this article, please hit the ❤️ like button.
If you think someone else will benefit from this, then please 🔁 share this post.
This was one of the clearest breakdowns I’ve read on global vs. local secondary indexes—especially the “scatter and gather” limitation and how partitioned GSIs solve for it. Loved the real-world query examples too. It’s easy to get lost in the abstractions, but this actually helped me visualize the flow. Would love to see a follow-up on how consistency tradeoffs play out between strong vs. eventual in large-scale systems. Great post, Sid.