
How to Handle Sudden Bursts of Traffic or "Thundering Herd Problem"?
Techniques to Avoid Potential Failures Caused by Sudden Traffic Spikes
What is the Thundering Herd Problem?
Imagine a scenario, where an event causes one or more of your services to experience an enormous surge in traffic, overwhelming their capacity. This can lead to one or more dependencies, such as a database, becoming overloaded and unresponsive, ultimately resulting in service failure (cascading failures). Such events could include multiple service instances failing and redirecting all traffic to a single instance, a viral image or video receiving huge viewership, or an online sale during a festival causing a database overload. This situation, where cascading failures lead to service unavailability due to a sudden spike in incoming traffic, is termed the Thundering Herd Problem.
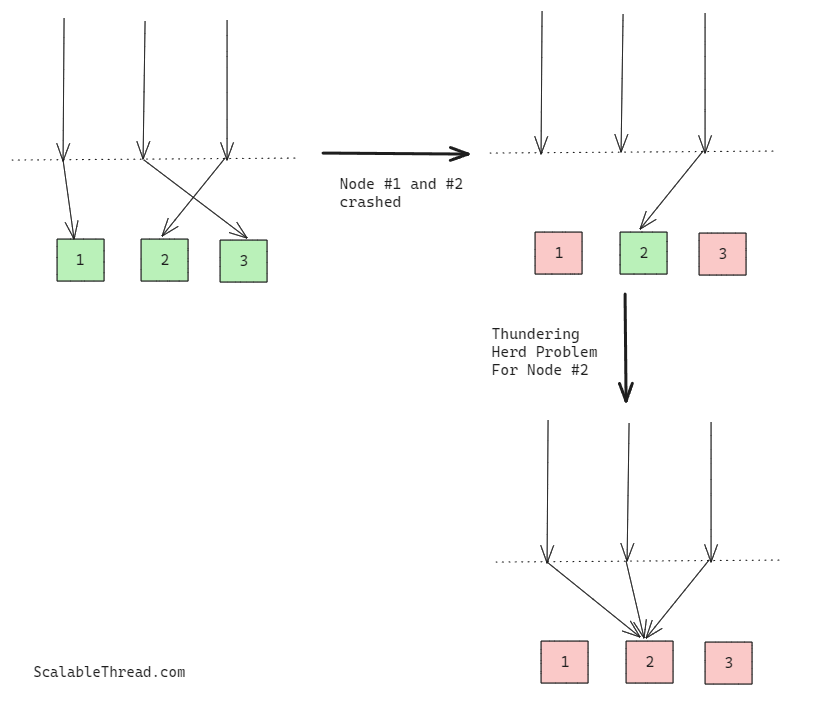
How to Handle the Situation?
Exponential Jitter and Retry
When a service fails to respond, the instinctive solution is to retry the request, assuming a transient failure. However, this approach can lead to the Thundering Herd scenario or exacerbate an existing one, as all clients retry simultaneously, overwhelming system resources. Instead, if clients retry at random intervals, the overloaded resource gets time to recover and respond. This randomness in retry timing, known as Jitter, helps distribute the load more evenly and prevents further strain on the system.

Queueing Requests
Consider a scenario where a request to fetch an image from the cache results in a miss, leading to the request being fulfilled from the origin datastore. If a large number of simultaneous requests experience cache misses and are forwarded to the data store, this can create the Thundering Herd problem. Since all the requests are for the same image, only a single request should be forwarded to the datastore for fulfillment. The remaining requests can be queued and served from the cache once it is updated after the initial request returns from the data store.

Load Balancing
Every large-scale application at some point requires service replication on the backend to handle increasing traffic. However, if this traffic is not evenly distributed across all service replicas, it can overwhelm specific instances. Using load balancers to distribute the load uniformly helps prevent the Thundering Herd problem.

Rate Limiting
If a service exposes APIs, providing unlimited access to its clients can be disastrous if one or more clients abuse it. Scenarios like DDOS attacks or scheduled batch jobs can trigger the Thundering Herd problem. Implementing rate limiting to control how frequently a client can call the API can help manage high-throughput clients and prevent such issues.

Circuit Breaker
A service dependency, such as a database, can fail due to the Thundering Herd problem. Similar to how an MCB (Miniature Circuit Breaker) protects a circuit by breaking it when there's a sudden spike in electric voltage, a service can implement a circuit breaker approach. This approach halts sending further outgoing requests to the dependency until it recovers and is ready to handle traffic again.

Load Shedding
While a circuit breaker allows a service to stop sending requests to a dependency, the dependency itself can drop incoming requests, a technique known as load shedding, to prevent the Thundering Herd problem. This is similar to rolling blackouts in the electrical world, where an electricity provider reduces the load to prevent a total system failure when demand exceeds capacity.

I have question on the topic of Queueing requests. Can you give a general idea how can we implement this? More specifically, how the other requests will know that there was already a request which misses the cache and trying to fill it and now we have to wait till that happen?
I have question but bit out of topic,
How do you manage burst traffic without impacted to p99 latency ?
from my experienece, spin off new instance tooks time due to "cold start"