
How Tool Calling Works in LLMs
Understanding the Internals of Tool Calling in Large Language Models
A Large Language Model’s (LLM’s) internal knowledge is limited to the data it was trained on, which can be outdated or lack direct access to real-time data, proprietary systems, or complex computational functions. Tool calling extends the capabilities of LLMs by allowing them to interact with external systems and access real-time or proprietary information.
What are the Tools in LLMs?
Tools are external functions or APIs a model can invoke to perform tasks beyond its inherent textual knowledge. These tasks include searching the web, performing calculations, accessing databases, sending emails, or interacting with other software services.
Example
Consider a large e-commerce platform's customer service chatbot powered by an LLM. When a user asks, "What is the shipping status of my order number 12345?" the LLM does not have direct access to the shipping information. A tool would be an API call to the platform's order-tracking system. The LLM, recognizing the user's intent, would call this tool, pass the order number (12345) as a parameter, and then receive the shipping status, which it can then communicate back to the user.
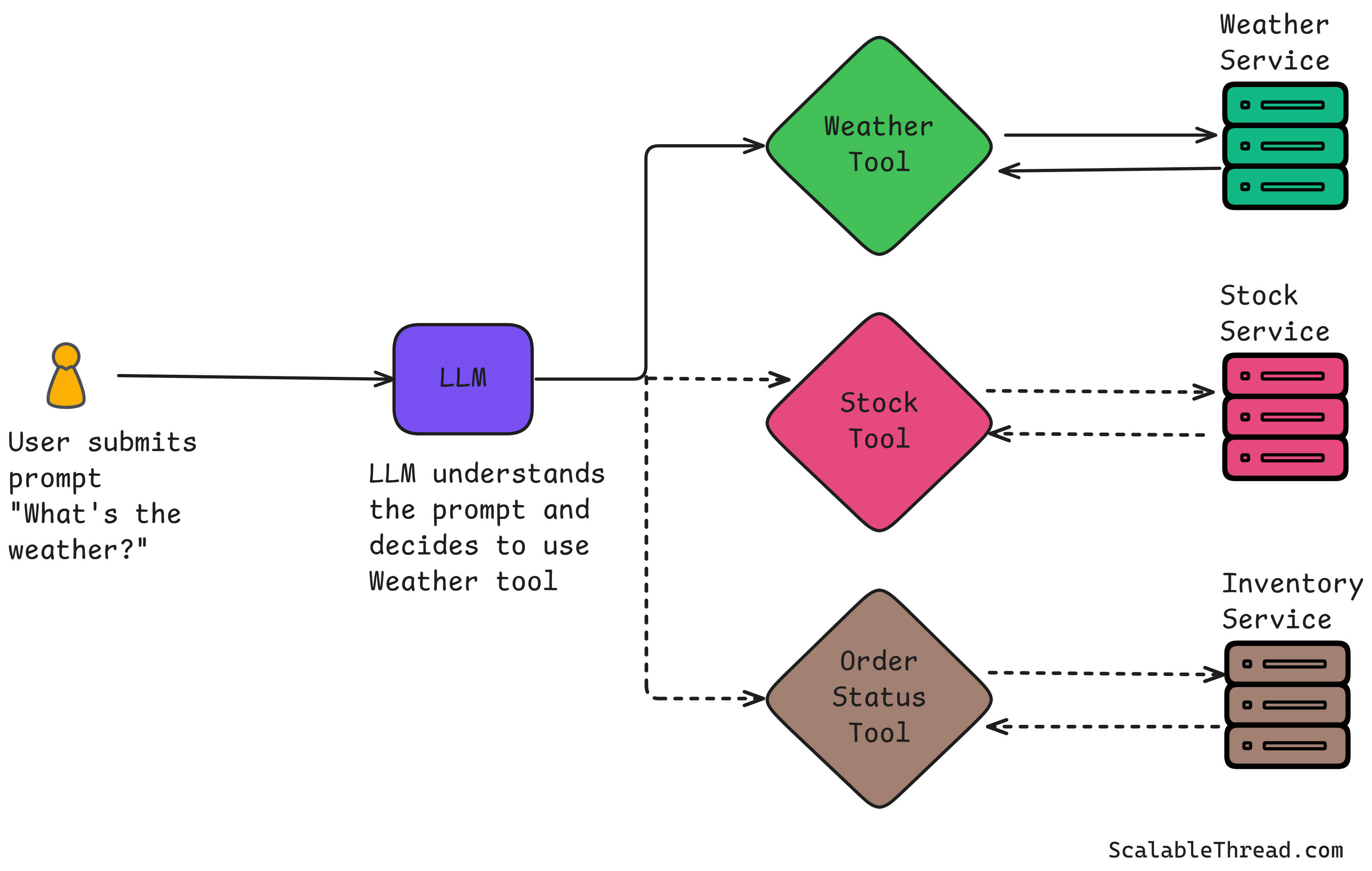
How Tool Calling Works
The process of tool calling involves a series of steps that begin with the user's prompt and end with the LLM generating a response that incorporates the tool's output.
How LLM Knows It Can Call a Tool
The LLM's ability to call a tool results from its training and the information provided during inference.
During Training: When an LLM is trained for tool calling, it's exposed to vast amounts of data where natural language queries are paired with corresponding tool calls and their expected outputs. The LLM develops a deep understanding of language patterns, semantic relationships, and intent through its pre-training on massive text data.
When it encounters tool definitions, it learns to associate specific patterns in user queries with the functionalities described by the tool. For example, if the toolgetCurrentWeatherhas the description "Fetches the current weather conditions," the LLM forms an internal association between phrases like "What's the weather," "temperature in," "Is it raining," and this tool. This isn't explicit programming but rather an association learned from the training data.During Inference: These tool definitions are explicitly provided to the LLM as part of its input prompt or context window. These definitions specify the tool's name, a description of what it does, and the parameters it expects. The LLM then processes these definitions alongside the user's query. This is similar to giving a human a list of available functions and their documentation before asking them to solve a problem.

Fig. A tool definition for an order tracking system

How LLM Decides When to Call a Tool
The decision to call a tool is based on the LLM's understanding of the user's intent and the information required to fulfill that intent. The LLM first processes the user's input and attempts to answer it using its internal knowledge base. Suppose the query can be answered directly from its training data (e.g., "What is the capital of France?"). In that case, it will proceed to generate a direct textual response.
However, if the query requires external, real-time, or proprietary information not present in its pre-trained weights (e.g., "What's the current stock price of Google?"), the LLM identifies this knowledge gap. Then, LLM analyzes the user's query to understand the intent (underlying goal or action). It then attempts to map this recognized intent to the available functionalities described by the tools. For instance:
User: "What's the weather in Tokyo?"
Intent: Get current weather information.User: "Book me a flight to New York for next Tuesday."
Intent: Initiate a flight booking process.
How LLM Decides Which Tool to Call
When multiple tools are available, the LLM selects the most appropriate one based on the user's query and the descriptions of the available tools. This decision is driven by the LLM's ability to match the semantic meaning of the user's request with the functionalities described in the tool definitions. The LLM might rank potential tools based on relevance scores or confidence levels. For example, if both a "weather forecasting tool" and a "stock price lookup tool" are available, and the user asks, "What's the current temperature in New York?" the LLM will favor the weather forecasting tool due to semantic similarity.
How Results from a Tool are Used
Once a tool call is executed, the external system returns a result. This result, often in a structured format like JSON, is fed back to the LLM. The LLM then integrates this new information into its context. It uses it to formulate an informative response to the user. In the e-commerce example, if the order tracking tool returns {"status": "Shipped," "estimated_delivery": "2025-06-25"}, the LLM would then generate a response like: "Your order number 12345 has been shipped and is estimated to be delivered by June 25, 2025."
If you enjoyed this article, please hit the ❤️ like button.
If you think someone else will benefit from this, please 🔁 share this post.
was hoping/reading for the part where the base LLM had enough smarts to parse multipart questions requiring callouts to multiple disparate tools and synthesis/re-presentation of their API data to provide the answer. Not one-shot/single question tool calls. Semantic parallelism.