
Why are Event-Driven Systems Hard?
Understanding the Core Challenges of Asynchronous Architectures
An event is just a small message that says, "Hey, something happened!" For example, UserClickedButton, PaymentProcessed, or NewOrderPlaced. Services subscribe to the events they care about and react accordingly. This event-driven approach makes systems resilient and flexible. However, building and managing these systems at a large scale is surprisingly hard.
Managing the Message Format Versions
Imagine you and your friend have a secret code to pass notes. One day, you decide to add a new symbol to the code to mean something new. If you start using it without telling your friend, your new notes will confuse them. This is exactly what happens in event-driven systems.
For example, an OrderPlaced event might look like this:
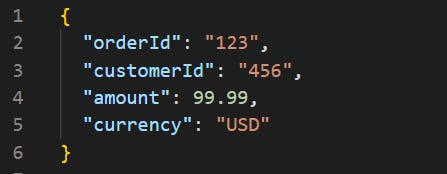
Now imagine another service reads this event to send a confirmation email. Then, six months later, you add a new field: shippingAddress. You update the producer. The event becomes:
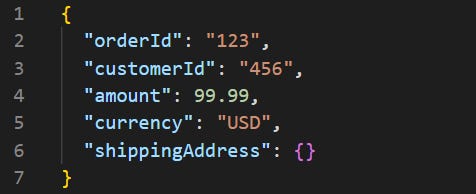
The problem is that other services, like the OrderConfirmationEmailService, might still be expecting the old version 1 format. When they receive this new message, they won't know what to do with the shippingAddress field. Worse, if a field they relied on was removed, they would simply crash.
This forces teams to carefully manage how schemas evolve. Common strategies include:
Backward Compatibility: New schemas can be read by services expecting the old schema. This usually means you can only add new, optional fields. You can't rename or remove existing ones.
Forward Compatibility: Services expecting a new schema can still read messages written in an old one. This is harder to achieve and often requires setting default values for missing fields.
Schema Registry: This is like a central dictionary for all your event "secret codes." Before a service sends a message, it checks with the registry to make sure the format is valid and compatible. It prevents services from sending out "confusing notes."
Without strict rules for changing message formats, a simple update can cause a cascade of failures throughout a large system.
Observability and Debugging
In a traditional, non-event-driven system, when a user clicks a button, one piece of code calls another, which calls another, in a straight line. If something breaks, you can look at the error log and see the entire sequence of calls, like following a single piece of string from start to finish.
In an event-driven system, that single string is cut into dozens of tiny pieces. The OrderService publishes an OrderPlaced event. The PaymentService, ShippingService, and NotificationService all pick it up and do their own work independently. They might, in turn, publish their own events.
Now, imagine a customer calls saying they placed an order but never got a confirmation email. Where did it go wrong?
Did the
OrderServicefail to publish the event?Did the
NotificationServicenot receive it?Did it receive the event but fail to connect to the email server?
Debugging this can be difficult as you can't see the whole picture at once.
To solve this, we use distributed tracing. When the very first event is created, we attach a unique ID to it, called a Correlation ID. Every service that processes this event or creates a new event as a result must copy that same ID onto its own work.
When you need to investigate a problem, you can search for this one correlation ID across all the logs of all your services. This allows you to stitch the story back together and see the journey of that single request across the entire distributed system.
Handling Failures and Message Loss
Events can disappear. Not because of bugs — because of infrastructure issues like network failure, a service crashing, or the message broker itself having a problem.
The core promise of many event systems is at-least-once delivery. This means the system will do everything it can to make sure your event gets delivered. If a service that is supposed to receive an event is temporarily down, the message broker will hold onto the message and try again later.
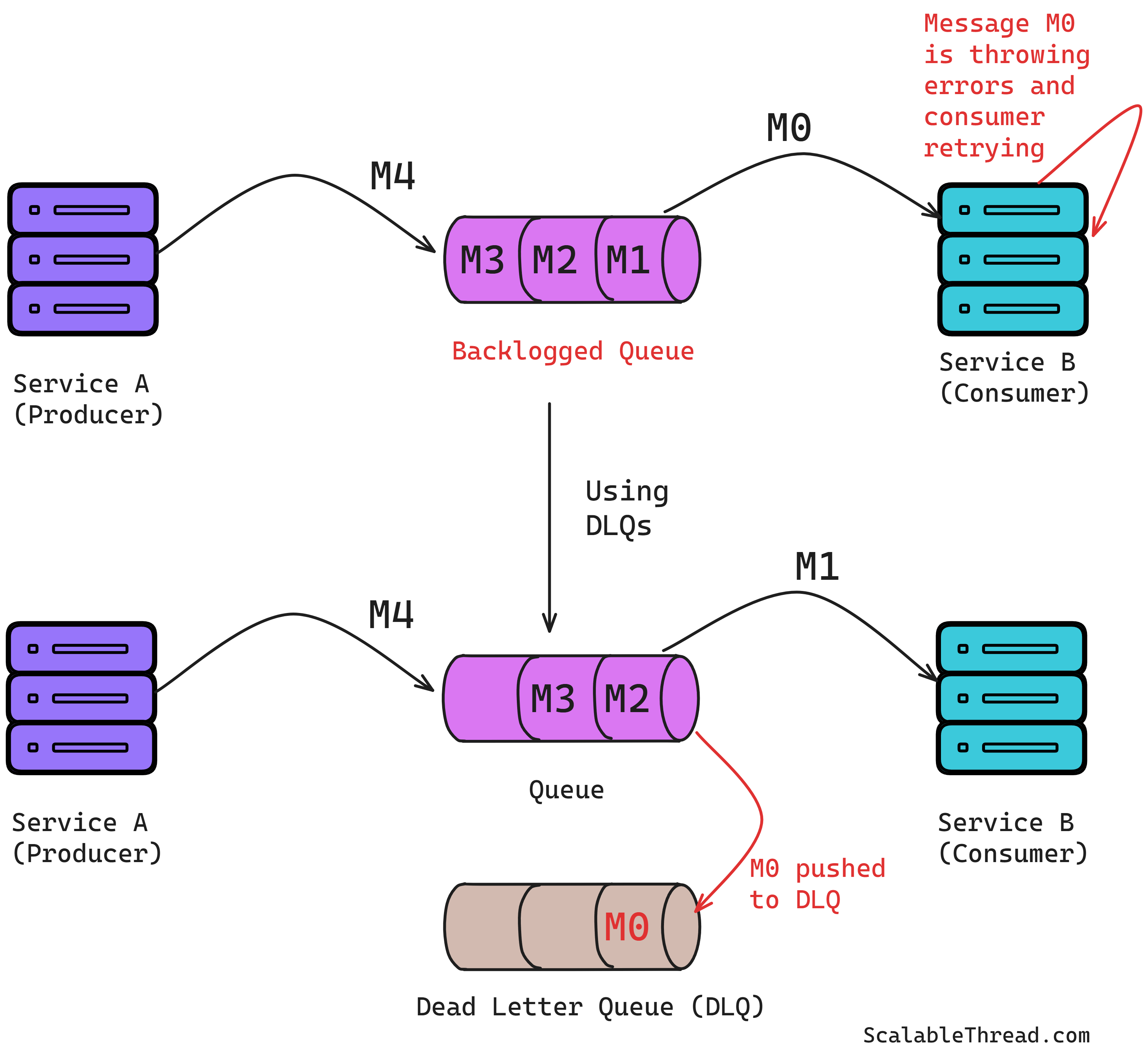
But what if a service has a persistent bug and crashes every time it tries to process a specific message? The broker will keep trying to redeliver it, and the service will keep crashing, until the broker retry limit is reached. To handle this, we use a Dead-Letter Queue (DLQ). After a few failed delivery attempts, the message broker moves the crash causing message to the DLQ. This stops the cycle of crashing and allows the service to continue processing other, valid messages. Engineers can then inspect the DLQ later to debug the problematic message.
Idempotency
The guarantee of "at-least-once delivery" creates a new, tricky problem: what if a message is delivered more than once? This can happen if a service processes an event but crashes before it can tell the message broker, "I'm done!" The broker, thinking the message was never handled, will deliver it again when the service restarts.
If the event was IncreaseItemCountInCart, receiving it twice is a big problem. The customer who wanted one item now has two in their cart. If it was ChargeCreditCard, they get charged twice.
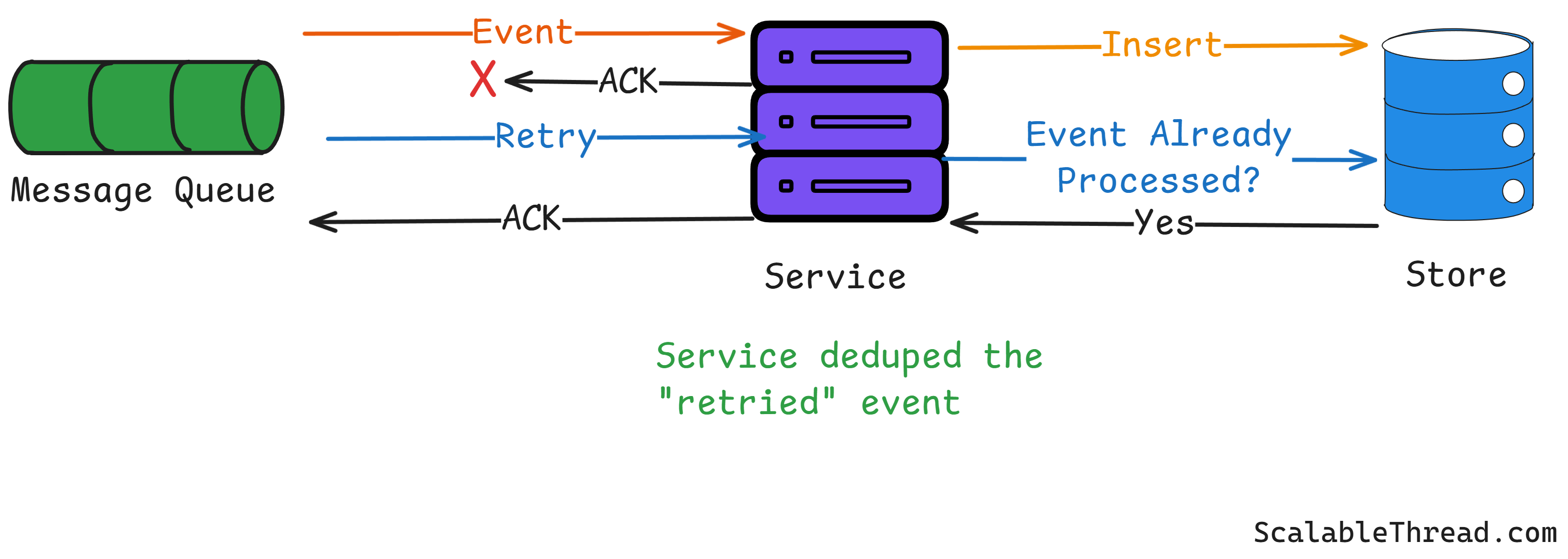
To prevent this, services must be idempotent. We can achieve idempotency by having the service keep a record of the event IDs it has already processed. When a new event comes in, the service first checks its records.
Has it seen this event ID before?
If yes, it simply ignores the duplicate and tells the broker, "Yep, I'm done."
If no, it processes the event and then saves the event ID to its records before telling the broker it's done.
This ensures that even if a message is delivered 100 times, the action is only performed once.
Eventual Consistency
In a simple application with one database, when you write data, it's there instantly. If you change your shipping address, the very next screen you load will show the new address. This is called strong consistency.
Event-driven systems give up this guarantee for the sake of scalability and resilience. They operate on a model of eventual consistency. For example, when a user updates their address, the CustomerService updates its own database and publishes an AddressUpdated event. The ShippingService and BillingService subscribe to this event. But it might take a few hundred milliseconds for them to receive the event and update their own data (This example is to provide some context, but ideally, the address should be stored at one place and the id of that record should be passed around in the events).
Designing for eventual consistency means the system must be built to handle this temporary state of disagreement. This might involve:
Designing user interfaces that account for the delay.
Adding logic to services to double-check critical data if needed.
Accepting that for some non-critical data, a small delay is acceptable.
If you enjoyed this article, please hit the ❤️ like button.
If you think someone else will benefit from this, please 🔁 share this post.
This is a great overview. Thanks for sharing your wisdom in such an easily-understood article.
I'd add one major category to this list: sequencing. The article talks about “services” placing items on a queue and being read by other “services”, but services generally consist of a set of nodes acting somewhat independently. If service B is consuming messages M1, M2, and M3 from a queue, and service B consists of three server nodes B1, B2, and B3, it’s possible that all three messages will be processed concurrently, with no guarantee that the effects of processing M1 will occur before M3 is processed on another node.
You can solve this by having only a single consumer, but that hits scaling limits. The usual solution is to partition the queue into sub-queues, each with its own ordering guarantee, and ensure that each partition is only delivered to a single consumer.
This is a good solution, but comes with its own challenges. For one thing, how many partitions do you use? There’s a balance: too few and it limits your scaling, too many and you waste resources on overhead. It’s can be hard to change this later: you can’t really change the number of partitions while the system is running and maintain your ordering guarantees, but most systems at the scale where this is important can’t stop running. The best solution I’ve found is to essentially create a new set of topics and consumers, and then transition the system from the old ones to the new ones. This is tricky in practice and of course quite costly to get right and even more costly to get wrong. I have to admit, though: it's been a few years since I've looked at this problem. Maybe newer message broker systems have better solutions.
This also relates to the issue of message loss and the dead-letter queue. If all of the messages are independent, a dead-letter queue can be a good approach, but what if the process for M3 assumes that you’ve already processed M1 and M2? For example, let's say M1 creates an order, M2 updates it, and M3 dispatches it. Best case scenario: you’ll also crash on M3 and deliver that to the dead-letter queue (such as if M1 wasn't processed, and there's no order to update or dispatch), but if you aren’t careful, it might just succeed but do the wrong thing (such as if M1 and M3 are processed, but not M2).
Then, there’s also the problem of ensuring that the messages are enqueued in the right order, which might also not be straightforward, depending on the design of the producing system.
I like event-driven architectures, and think they can have a lot of benefits that outweigh the cost of these challenges (in the right use cases). I just think it's important that people go into these system design decisions with full awareness of the tradeoffs they're signing up to.
What about adding a version number to my event and asking each service number to raise an error, if the assumed version number does not match the expected one?