
How to Handle Concurrency with Optimistic Locking?
Understanding How Distributed Systems Avoid Race Conditions
What is Optimistic Locking?
Managing concurrent access to shared resources is a critical challenge in distributed systems. Conflicting updates can lead to data corruption and inconsistency. Optimistic locking operates on the principle of "assume no conflict, but verify." Instead of preventing conflicts by acquiring locks upfront, transactions can proceed. It only checks for conflicts at the point of committing changes. This process typically involves three distinct phases:

Read Phase
A transaction reads data from the data store without acquiring any locks on the resources. The system notes the data's version at the time of the read, which can be a timestamp, a version number, or a checksum. The transaction then computes and prepares any intended modifications based on this read data.
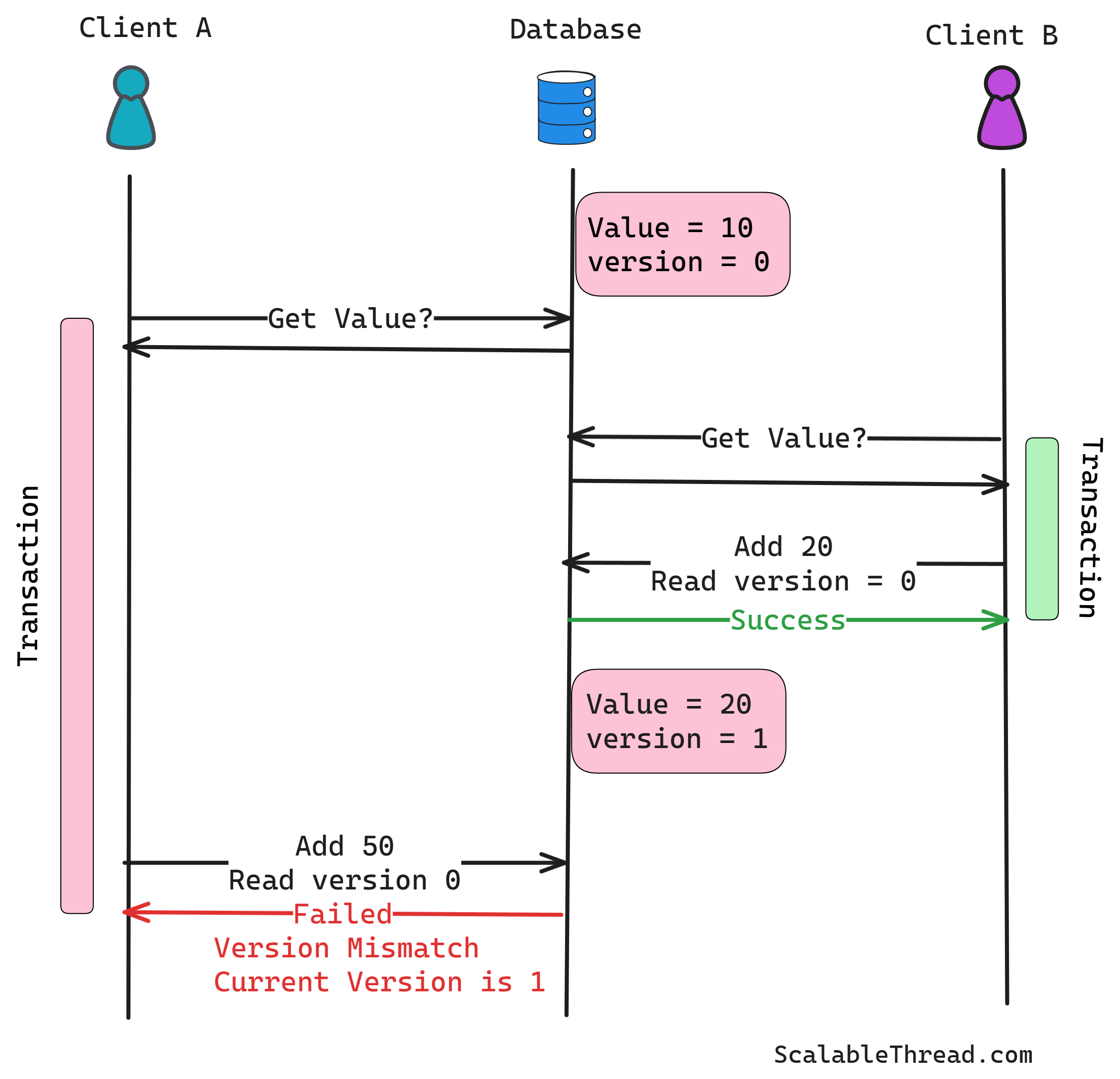
For example, consider a distributed product inventory system. When a user attempts to update a product's stock level, the system first reads the current stock count and its associated version number. Let's say Product A has a stock of 100 and a version number of 5.
Validation Phase
Before committing any changes, the transaction enters the validation phase. Here, the system checks if any other concurrent transaction has modified the data read in the first phase. This is done by comparing the version of the data noted during the read phase with the current version of the data in the data store. If the versions match, it implies that no other transaction has altered the data, and the current transaction can proceed. If the versions differ, another transaction has modified the data in the interim, leading to a conflict.
For example, before updating the stock of Product A to 90 (due to a sale), the system checks if the version number for Product A in the database is still 5.
Write Phase (or Rollback)
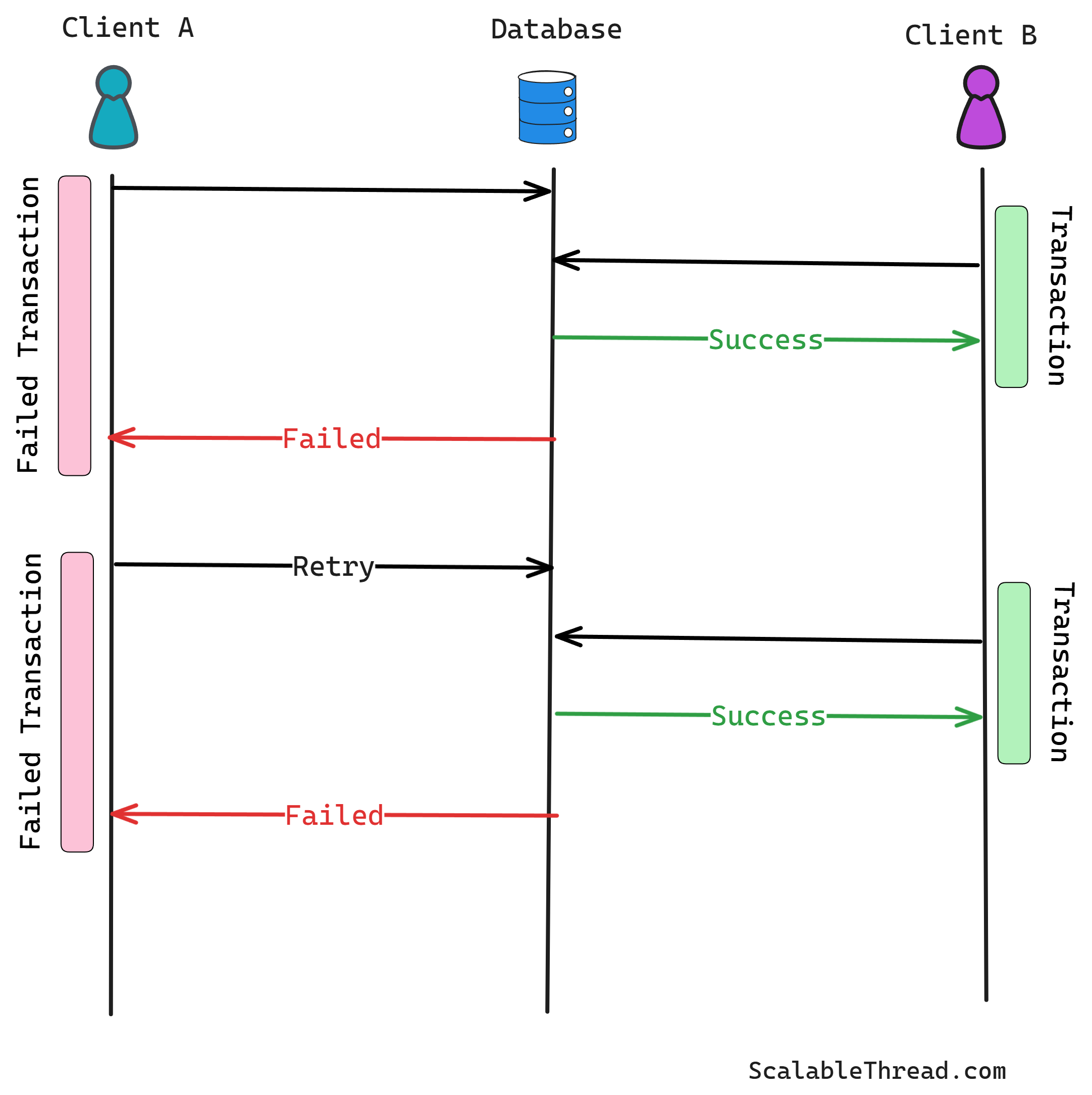
If the validation phase is successful (no conflict detected), the transaction proceeds to the write phase. The prepared changes are applied to the data store, and the version of the modified data is updated (e.g., the version number is incremented). This makes the changes visible to other transactions. If the validation phase detects a conflict, the transaction is aborted or rolled back. The application then needs to decide how to handle this conflict – it might retry the entire transaction, notify the user, or apply a specific conflict resolution strategy.
When to Use Optimistic Locking
Low Contention Environments
The core assumption of optimistic locking is that conflicts are rare. Therefore, it shines in systems where the probability of multiple transactions attempting to modify the same piece of data simultaneously is low.
Read-Heavy Workloads
Systems where data is read frequently but modified infrequently benefit greatly from optimistic locking. Read operations do not require locks, allowing for high concurrency and responsiveness.
High Concurrency Requirements
By not holding locks for extended periods (or at all during the read and computation phases), optimistic locking allows a greater number of transactions to proceed concurrently. This can significantly improve system throughput.
Systems Where Retries are Acceptable
Since conflicts lead to transaction rollbacks, the application must be designed to gracefully handle these retries. Suppose the cost of retrying a transaction is low and the conflict rate is minimal. In that case, optimistic locking is an efficient choice.
Problems with Optimistic Locking
Potential for Starvation
Suppose a particular piece of data is highly contended. In that case, some transactions attempting to update it might repeatedly fail validation and get rolled back, leading to starvation for those transactions. Frequent conflicts can also lead to significant performance degradation due to repeated rollbacks and retries.
Complexity in Handling Retries
The application logic must be robust enough to handle transaction failures and implement retry mechanisms. This can add complexity to the application development. Deciding on the appropriate retry strategy (e.g., number of retries, backoff period) is crucial.
Data Validation Complexity
Ensuring that the validation check is comprehensive and correct is critical. The validation logic can become intricate for complex transactions involving multiple data items.
If you enjoyed this article, please hit the ❤️ like button.
If you think someone else will benefit from this, please 🔁 share this post.
What if another transaction modified the data after the validation step succeeded but before the transaction commits?