
How to Handle Hot Shard Problem?
Understanding Different Approaches to Address Hot Key/Partition Problem
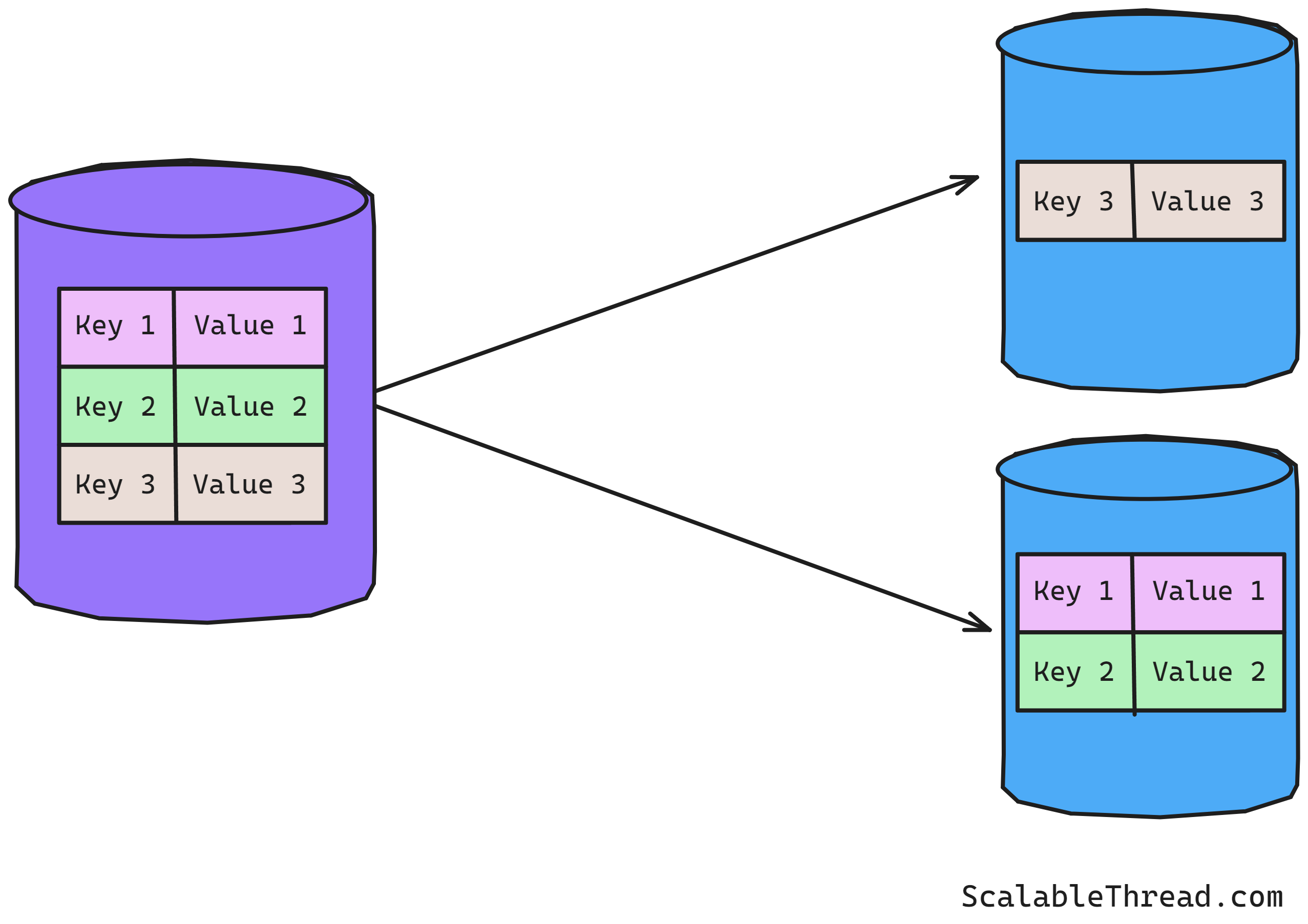
What is Sharding?
Software applications with growing data eventually reach a point where they start experiencing memory, storage, or network limitations, which impact the overall performance and availability of the system. The data no longer fits on the existing node(s). To overcome these limitations, data must be moved to a bigger machine (monolith) or split into chunks and distributed across multiple machines/shards (sharding). The goal with sharding is to make sure data is distributed across enough machines/shards to avoid any resource constraints that could impact the performance of the data operations.
What is Hot Shard Problem?
Once data is sharded to multiple nodes, there can be scenarios such as thundering herd problem or co-location of high throughput accounts, where most read or write requests are on the same shard. This can lead to the following situations:
Memory Saturation: The impacted shard will run out of RAM to hold the warmed data. To address this, RAM will start paging the data in the memory to the disk. Reading that data will require pulling those pages back from the disk to the memory. This to-and-fro from the memory to the disk and vice versa will impact the overall read and write performance of the shard, which will end up creating a backlog of requests or, even worse, making the shard unresponsive.
CPU Saturation: If the read or write queries are compute-intensive, there may be a backlog of requests as the CPU needs time to complete a single query. In a single-threaded system, it may even end up spending more time on context switching between different tasks than on the tasks themselves.
Network Saturation: A node's bandwidth is also a limited resource. It can be exhausted if the amount of data requested from the node exceeds its network bandwidth capacity.
This scenario of a shard's resource saturation resulting in a backlog of requests is often referred to as a Hot Shard or a Hot Partition or a Hot Key Problem.

How to Handle the Situation?
Some of the approaches to handle the Hot Shard Problem:
Scale Vertically
One obvious solution is to increase the node's size by allocating more resources to it. This vertical scaling may not prove to be an ideal solution in the long term, but it can help mitigate the problem.
Use Read Replicas or Cache
In a scenario where the hot sharding issue is caused by the read queries, using a cache may be helpful in a scenario where the query response doesn't change. In situations where the cache doesn't help, and all reads and writes are being served through the primary node, having separate read replicas for the primary node will free up the primary node by distributing the read load across read replicas. This approach may or may not experience eventual consistency based on the consistency model applied to the system.

Use a Large Number of Nodes from the Start
This solution may not last longer if the application is experiencing exponential growth. Allocating a large number of extra nodes at the start may also prove to be expensive and a waste of resources.
Queueing and Load Balancing
In addition to the read replica solution above, read requests can be load-balanced across multiple read replicas.
On the other hand, if a sudden spike in traffic causes the hot shard, if the system allows, write requests can be queued to allow the system some buffer.
Control the Traffic
To avoid surprises, the system's anticipated load should be calculated in advance, and capacity should be allocated based on that, along with some extra buffer for regular spikes. Mechanisms such as backpressure, etc., can be used to control input traffic.
Degraded Mode
In this scenario, the system can focus on requests with higher priority and drop, queue, or rate limit the requests with lower priority. This will allow the system to reduce the load and continue operating in a degraded mode. For example, in degraded mode, an email application can prioritize sending emails over showing whether the user is online.

Move Hot Keys
One ideal solution is to distribute the hotkeys across different shards to distribute the load uniformly. The hotkey can also be moved to its own shard if needed. However, adding a new shard can cause another set of problems. Approaches like consistency hashing can allow adding a new shard with minimal impact on the existing data organization.
Choose the Right Sharding Key and Algorithm
The sharding key is core to partitioning and distributing data across shards. A sharding key should allow for many possible distinct values (high cardinality), with each value having a similar probability of occurrence, allowing for a uniform data distribution. The application's query pattern should also be considered when selecting the sharding key to avoid/reduce cross-shard data access. Similarly, using a sharding algorithm, such as consistency hashing etc., that has a low probability of conflicts or collisions and allows for changes in data distribution, can be helpful.
Monitor the Cluster
Set up metrics to monitor spikes in latency, disk reads, CPU utilization, etc., to ensure the existing sharding strategy works correctly and detect any anomalies promptly.
If you enjoyed this article, please hit the ❤️ like button.
If you think someone else will benefit from this, then please 🔁 share this post.
Good read.