
How to Keep Services Running During Failures?
Strategies for Graceful Degradation in Large Scale Distributed Systems
In software applications, a server can fail, a database can become unresponsive, or a sudden traffic surge can overload the system. Most of the time, this is bad news. But what if there was a way to survive the chaos? What if your app, instead of crashing completely, could keep its cool and deliver a working, if slightly reduced, experience? This is where Graceful Degradation comes into the picture.
Graceful degradation is a design principle where a system maintains essential functionality even when parts of it fail. Instead of crashing completely, the system operates at a reduced capacity. For example, on a video streaming platform, if the recommendation service fails, the platform shouldn't crash. Instead, it might gracefully degrade by showing a generic list of popular videos rather than personalized suggestions. The core function—video playback—remains available.
Strategies for Graceful Degradation
Implementing graceful degradation requires a combination of strategies that control traffic, manage failures, and provide visibility into the system's health.
Rate Limiting or Request Throttling
Think of rate limiting or request throttling as a bouncer controlling the traffic to your servers. During a huge flash sale or a denial-of-service attack, your system can be flooded with requests. A rate limiter lets a certain number of requests in and tells the rest to come back later. This simple move stops a server from overloading or failing with many incoming requests.

Request Coalescing
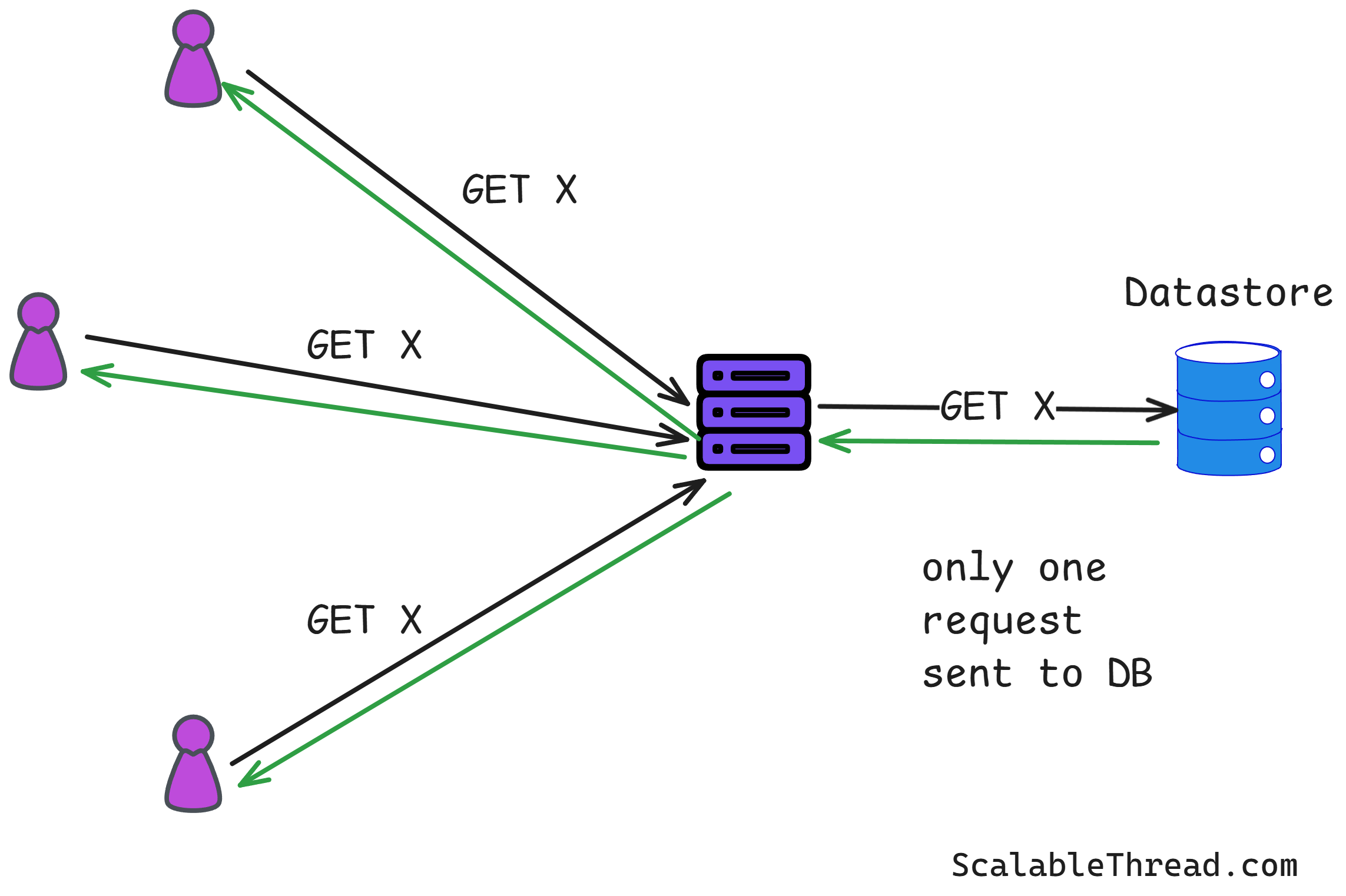
If thousands of people hit submit on an application to get the same data, instead of sending thousands of identical queries to your database or datastore, you send just one. You get the answer and then distribute it to everyone who was waiting. It's efficient, saves resources, and keeps your system from getting bogged down with repetitive tasks.
Request Drops or Load Shedding
Sometimes, you just can't serve everyone. In those moments, load shedding becomes a necessity. This is the act of dropping non-critical requests to save the most important ones. For an e-commerce site, this means prioritizing a user's final purchase over an analytical request to log their click.

Jitter and Retry
When a service fails and then recovers, a huge list of waiting clients will try to connect all at once. This is a classic thundering herd problem, and it can immediately crash the service all over again. The solution is retry with jitter. Instead of all clients retrying at the same time, you add a small, random delay. This distributes the requests over a period of time instead of sending all requests at the same time, giving the service time to recover completely.

Circuit Breakers
This pattern is just like the electric circuit breaker in your home. If a service keeps failing, you open the circuit. All subsequent requests to that service are immediately blocked for a set period. This saves resources, provides an instant failure response to the user, and gives the broken service time to heal. After a timeout, it slowly lets a few requests through to see if the service is healthy again. If they succeed, the circuit closes, and normal operation resumes. If they fail, it opens again.
Consider an architecture where an Order Service needs to call a Payment Service. If the Payment Service becomes unresponsive, the circuit breaker in the Order Service will open. For the next 60 seconds, any attempt to process a new order will instantly fail without trying to contact the Payment Service, saving resources and providing a fast failure response to the user. After 60 seconds, it will let one request through to test the connection.
Request Timeouts
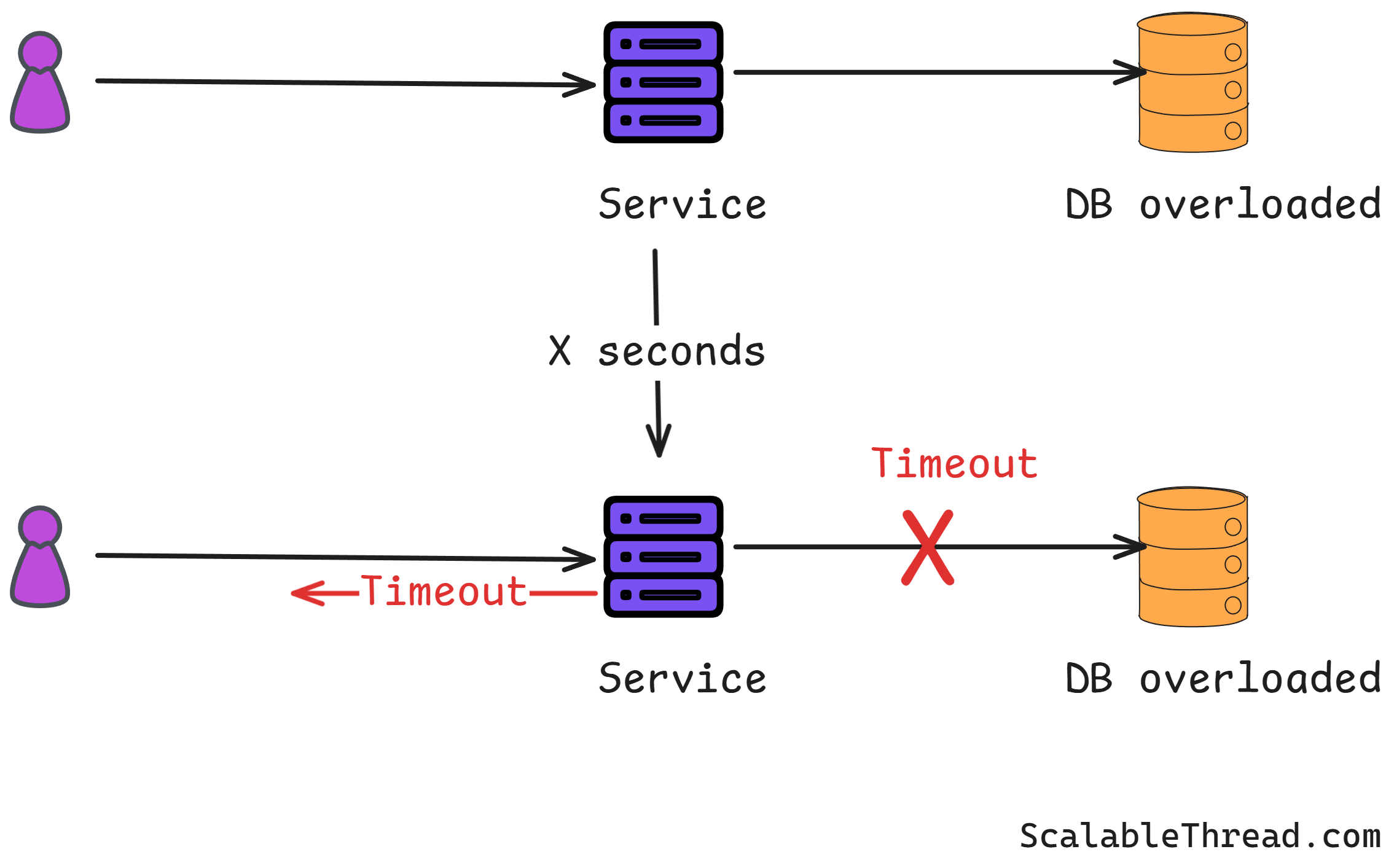
A client application should not wait indefinitely for a response from a service. If a response isn't received within a configured time frame, the request should be abandoned, and resources should be freed up. This prevents a slow or unresponsive downstream service from causing resource exhaustion (like holding onto threads or connections) in the upstream service.
Monitoring and Alerts
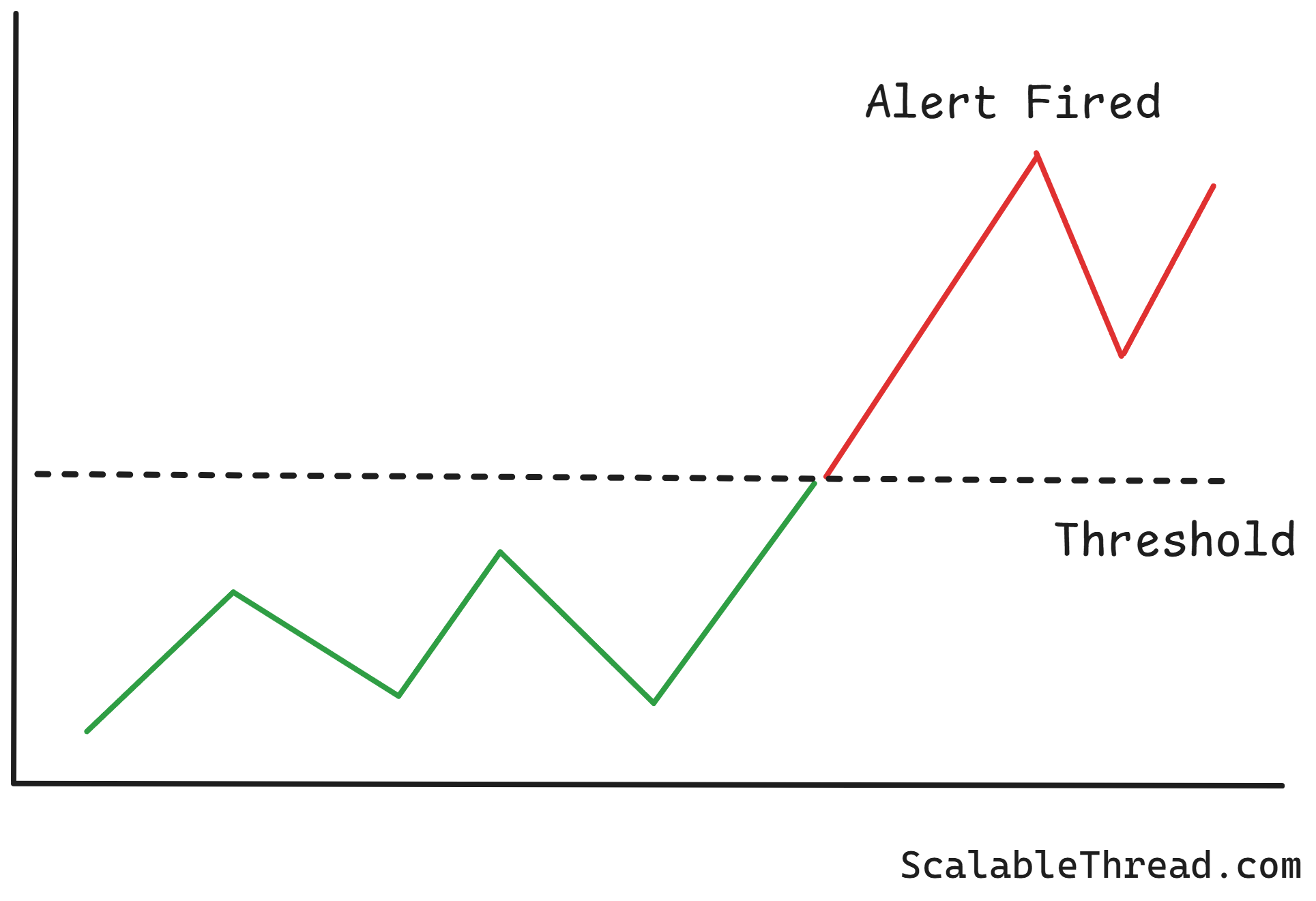
Monitoring and alerting are important for detecting failures before they escalate. This involves collecting metrics (e.g., error rates, latency, CPU utilization), logs, and traces from all system components. Alerting systems are configured on top of this data to notify engineers when key metrics cross dangerous thresholds. This allows for proactive intervention and quick diagnosis of problems.
A team running a large data processing pipeline would monitor the queue length of their message broker. Suppose the number of messages in the queue suddenly starts growing rapidly. In that case, an alert is triggered and sent to the on-call engineer. This indicates that a consumer service is failing or is too slow, allowing the engineer to investigate and resolve the issue before the system runs out of memory or data processing falls too far behind.
If you enjoyed this article, please hit the ❤️ like button.
If you think someone else will benefit from this, please 🔁 share this post.
Usually I would roll back my service