
How Transaction Isolation Provides Data Integrity in Databases
Understanding Different Transaction Isolation Levels in Databases
The Problem
Transactions are a fundamental aspect of ACID-compliant databases. They consist of a series of operations executed atomically—completed in full or rolled back entirely. Most modern databases support parallel connections, enabling multiple clients to run transactions simultaneously. As a result, various scenarios can arise:
Scenario #1: Two clients, say Client A and Client B, try to read or update data items in different databases or tables
Scenario #2: Client A and Client B try to read or update the same data item concurrently
Scenario #1 is straightforward and doesn’t lead to any data integrity issues. However, in scenario #2, let’s say transaction A tries to update multiple rows from state X to state Y. At a point when transaction A has updated 50% of the rows in the database to state Y (the remaining are still state X and transaction A is still running), transaction B to update the rows from state X to state Z occurs concurrently. This leads to the following questions for the database:
Should transaction B consider the original state (state X) of rows being updated by transaction A?
Should transaction B consider the new state (state Y) of rows being updated by transaction A?
Should transaction B wait for transaction A to complete before proceeding?
This is where Transaction Isolation allows the database to control the order of execution of concurrent transactions.
Different Transaction Isolation Levels
Read Uncommitted
This isolation level allows a transaction to read data that the other transaction hasn’t yet committed. In Read Committed mode, the locking of data being updated is avoided or not honored. As a result, this can lead to Dirty Reads — a scenario where transaction A makes an update that is not committed yet, and a concurrent transaction B reads it, after which transaction A triggers a rollback and drops the updates. Read Uncommitted mode provides the highest performance as no locking is involved. However, this mode should mostly be preferred when the data is not expected to be modified.

Read Committed
As the name suggests, the Read Committed mode doesn’t read uncommitted data and guarantees that only the committed data from other transactions will be read. This solves the issue of Dirty Reads. In this isolation level, a query in a transaction only sees the data committed before the query began, not the changes committed during query execution by any concurrent transaction. However, the data can change during the interval between multiple queries in a transaction. This leads to the Non-Repeatable Reads scenario, where a transaction reading the data multiple times with different queries may get different data values for each query if any concurrent transaction updates the data after it was read by one query but before the second query in the transaction read it. This is a default isolation level in PostgreSQL.

Repeatable Read
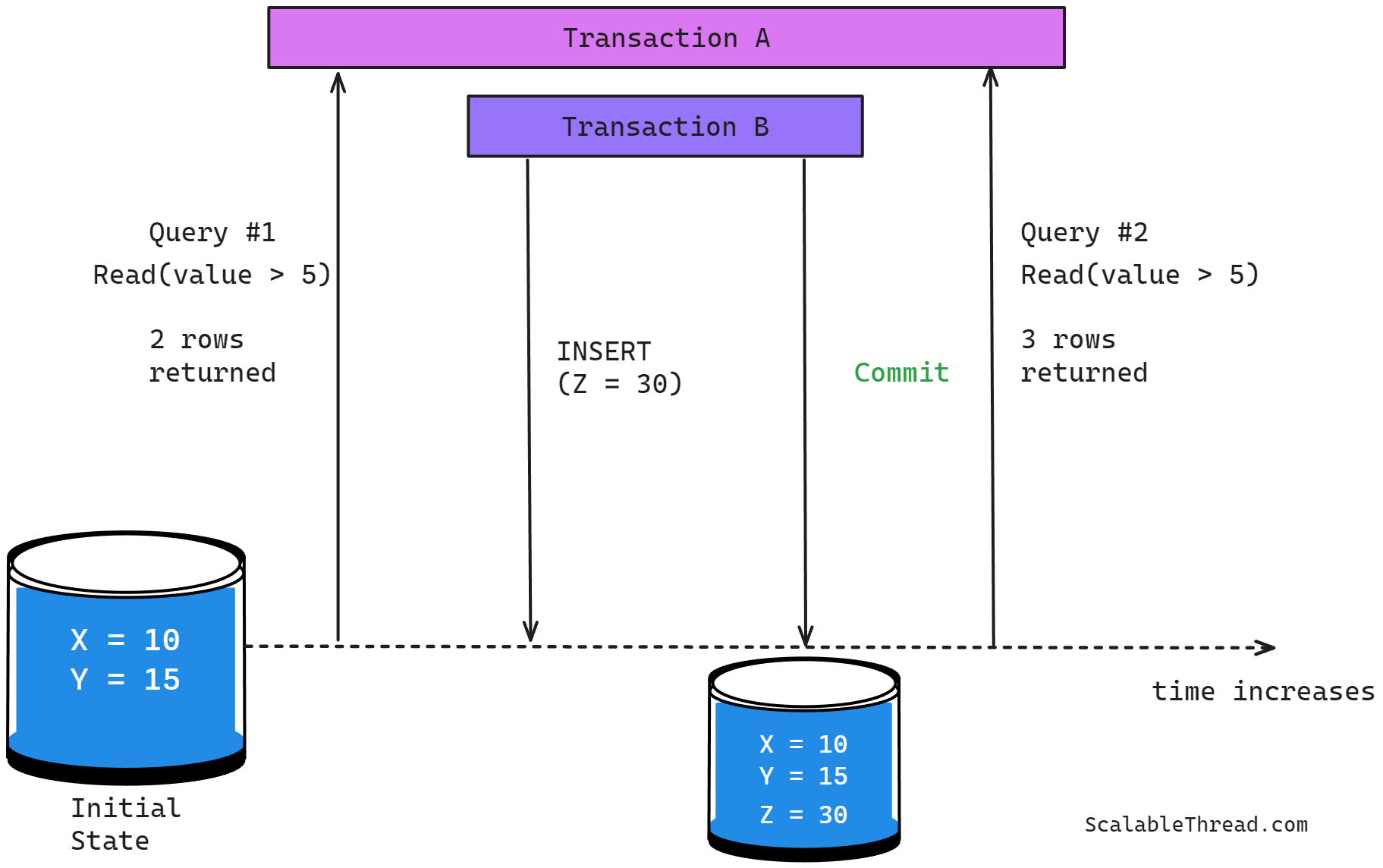
Unlike Read Committed, this isolation level allows multiple queries in a transaction to read a row multiple times with the same data value each time, thus solving the issue of non-repeatable reads. It guarantees that data read by transaction A cannot be changed by any concurrent transaction B until transaction A is complete. However, new rows may still be added, or existing ones may be removed by any concurrent transaction, which can lead to the Phantom Reads Scenario, where a transaction A running a read query twice gets a different set of rows because a concurrent transaction B added or deleted rows after the first query in transaction A is completed but before the second query in transaction A starts. In this scenario, the data values of the rows have not changed to avoid non-repeatable reads, but the set of rows satisfying the query constraints has changed.
Serializable
Serializable isolation is the most strict isolation level, preventing dirty reads, non-repeatable reads, and phantom reads. It guarantees that no new data is seen by subsequent reads in the same transaction. Any concurrent transactions in this mode are guaranteed to produce the same outcome as running them one at a time in a serial order. However, this serializability comes at a performance cost.

References
13.2. Transaction isolation. (2024, November 21). PostgreSQL Documentation. https://www.postgresql.org/docs/current/transaction-iso.html
No Dirty Reads: Everything you always wanted to know about SQL isolation levels (but were too afraid to ask). (n.d.). https://www.cockroachlabs.com/blog/sql-isolation-levels-explained/
Read Committed Isolation Level. (2012, January 1). PostgreSQL Documentation. https://www.postgresql.org/docs/7.2/xact-read-committed.html
Transaction Isolation Levels and why we should care | Metis. (n.d.). https://www.metisdata.io/blog/transaction-isolation-levels-and-why-we-should-care
Your articles are 🤩
The REPEATABLE READ isolation level can lead to deadlocks in two common scenarios:
Scenario 1:
• Transaction A reads a data item, then tries to write to it.
• Transaction B reads the same data item, then tries to write to it.
Here’s what happens:
1. Both transactions start by acquiring S-locks (shared locks) on the data item for their read operations.
2. When they try to write, both need to upgrade their S-locks to X-locks (exclusive locks).
3. Transaction A can’t upgrade because Transaction B is holding an S-lock, and Transaction B can’t upgrade because Transaction A is holding an S-lock.
4. Neither can proceed, causing a deadlock.
Scenario 2:
Similar to Scenario 1, but the deadlock arises because transactions read and then write to the same data item. The sequence of acquiring an S-lock for the read and then requesting an X-lock for the write creates contention.
To avoid these deadlocks:
1. Minimize read-before-write patterns in transactions.
2. Use X-locks directly if you know a write will follow the read.
3. Implement retry mechanisms to handle deadlocks when they occur.