
Understanding Faults and Fault Tolerance in Distributed Systems
How Things Can Break in Distributed Systems
Software applications rely on distributed systems for data storage, computation, and real-time processing. These systems spread workloads across multiple nodes (servers, databases, or services) to improve scalability and availability. However, distributed systems face a critical challenge: faults. Their inherent complexity makes them susceptible to various types of failures. Fault tolerance is the ability of a system to continue operating correctly despite faults in some of its components.
What Are Faults and Why Do They Occur?
A fault is a defect in a system component that can lead to an error (incorrect state) and, eventually, a failure (deviation from expected behavior). Faults in distributed systems can be categorized into several types:
Hardware Faults: Physical failures like disk crashes, RAM corruption, or power outages.
Example: A server in a cloud cluster loses network connectivity due to a faulty router.
Software Faults: Bugs in code, race conditions, or memory leaks.
Example: A microservice crashes after encountering an unhandled null pointer exception.
Human Errors: Misconfigurations, accidental data deletions, or flawed deployment scripts.
Example: A developer deploys a buggy update that corrupts a distributed cache.
Network Faults: Packet loss, latency spikes, or partitions (split-brain scenarios).
Example: A database replica in Europe becomes unreachable due to an undersea cable cut.
Environmental Faults: Natural disasters, power grid failures, or overheating data centers.
Byzantine Faults: These are the faults where a component behaves arbitrarily, potentially sending conflicting or malicious information to different parts of the system. This can be due to hardware errors, software bugs, or even malicious attacks.
Impact of Faults
When faults occur in a distributed system, they can impact the overall system functionality and user experience.
Data Loss: A critical impact of hardware failures, especially disk drive failures, can be the permanent loss of valuable data if proper replication mechanisms are not in place. Software bugs leading to incorrect data updates or deletions can also result in data loss.
Service Unavailability: If a critical component of the system fails, its service might become unavailable to users.
Performance Degradation: Faults can lead to a decrease in performance. For example, network delays can slow communication between components, and failed nodes might need to be bypassed or their workload redistributed, adding overhead to the remaining nodes.
Inconsistent State: Faults, particularly network partitions, can lead to inconsistent views of the data or the system's state among different parts of the system.
Security Breaches: In some cases, faults can be exploited by malicious actors to compromise the system's security.
How to Achieve Fault Tolerance?
Replication
This involves creating multiple copies of critical data or components across different nodes. If one replica fails, others can take over, ensuring continued availability and data durability.
Active Replication: All replicas process incoming requests concurrently. This provides low latency failover but requires careful coordination to ensure consistency. For example, a load balancer distributes incoming user requests to multiple identical application servers. If one server fails, the load balancer simply directs traffic to the remaining healthy servers.

Fig. Active Replication - Node Failover Passive Replication (Standby): One replica is designated as the primary, handling all requests. Secondary replicas remain idle and are activated only when the primary fails. This may have a higher failover latency. For example, a primary database server handles all write operations, while a secondary server continuously receives updates. If the primary fails, the secondary is promoted to become the new primary.

Fig. Passive Replication - Database Failover
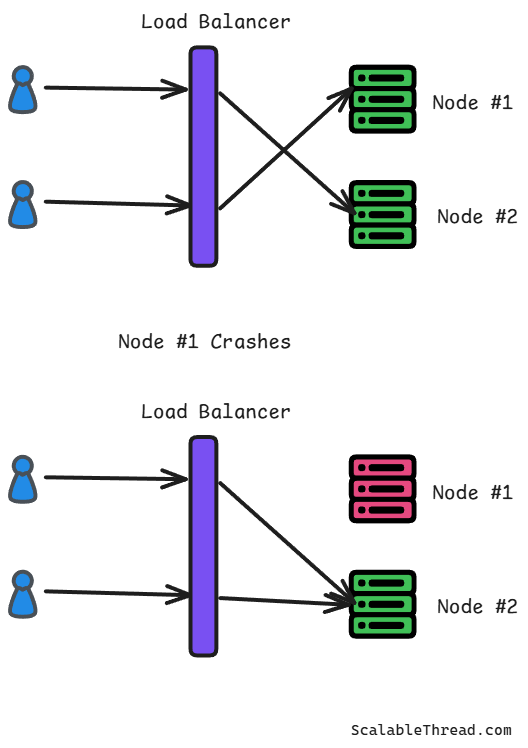

Failure Detection and Recovery
This includes having mechanisms to detect when a component has failed.
Heartbeats: Periodic messages sent by a component to indicate its health. The absence of a heartbeat within a certain timeout period indicates a failure.

Fig. Heartbeats Checkpointing: Periodically saving the state of a system or component (checkpointing) allows for recovery from failures by restoring the last saved state.

Fig. Checkpointing


Retries and Timeouts
Exponential Backoff: Retry failed requests with increasing delays (jitter) to avoid overwhelming the system.

Fig. Exponential Jitter and Retry Circuit Breakers: Temporarily block requests to a failing service or component until it recovers and is ready to handle traffic again.

Fig. Circuit Breaker Timeouts: Setting time limits for expected responses. The sender assumes a failure if a response is not received within the timeout.
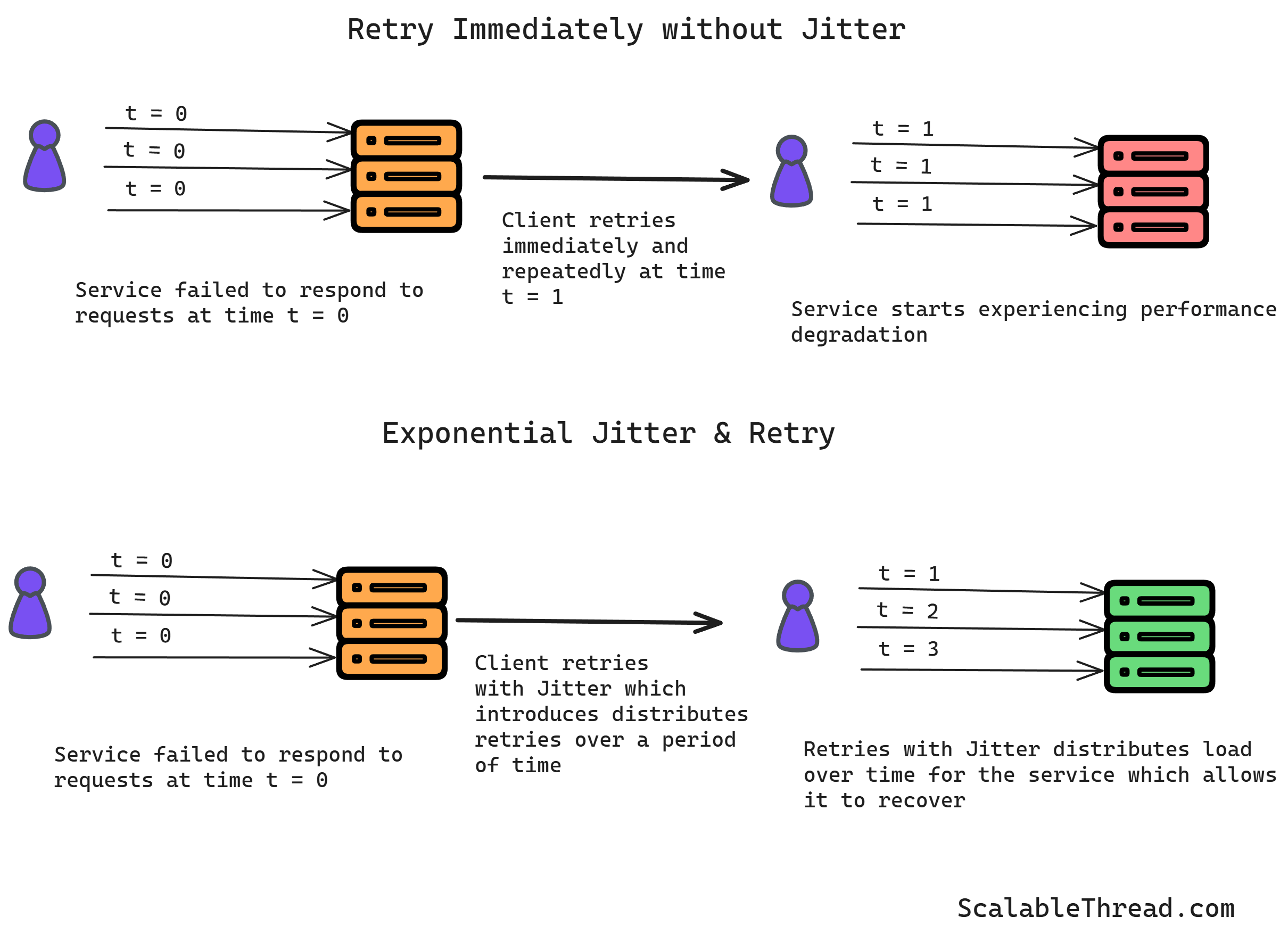

Idempotency and Quorum
Idempotency: Designing operations that can be executed multiple times without unintended side effects. This is particularly important when dealing with potential message loss or retries in distributed systems.
Quorum Systems: Require a majority of nodes to agree before committing changes. This ensures that the system can tolerate a certain number of failures while still maintaining consistency.

Fig. Leaderless Replication — Client sends updates to all five nodes and considers success if any three of them acknowledge (Quorum)

If you enjoyed this article, please hit the ❤️ like button.
If you think someone else will benefit from this, then please 🔁 share this post.