
Why is Cache Invalidation Hard?
Understanding the Hidden Complexity of Cache Invalidation in Distributed Systems
Caches are critical for optimizing performance in software applications. They reduce latency and improve scalability by storing copies of frequently accessed data closer to users or applications. For example, a global e-commerce platform might cache product catalogs to avoid repeated database queries, cutting response times from hundreds of milliseconds to microseconds. Without caching, high traffic volumes would overwhelm datastores, causing delays or outages. Caches also reduce operational costs by minimizing compute and storage load on primary systems.
What is Cache Invalidation?
Cache invalidation ensures that the data stored in the cache is up-to-date and consistent with the original data source. When the original data changes, the corresponding entry in the cache must be either removed or updated to reflect the change. This is crucial because if the cache contains stale data (data that is no longer accurate), users might receive incorrect information, leading to inconsistencies and potential errors in the system.
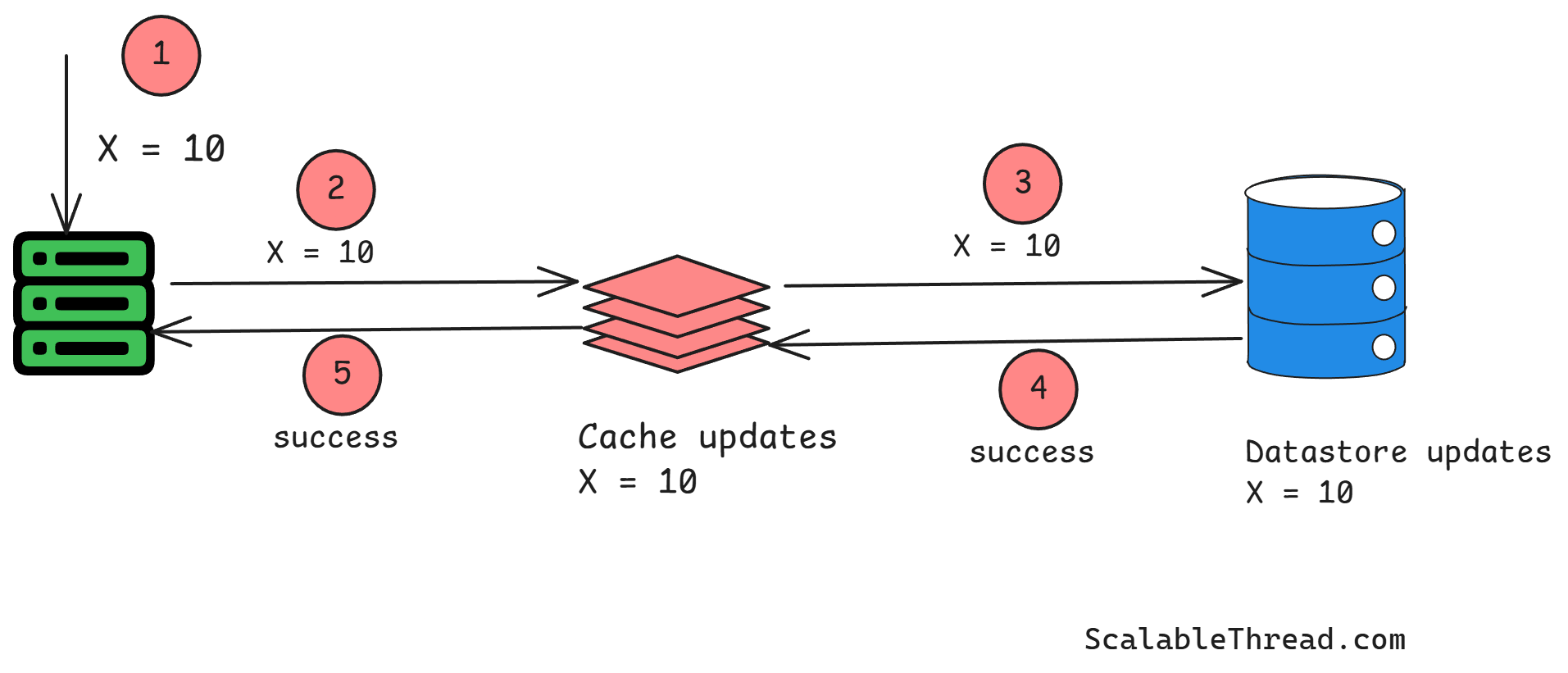
Why is Cache Invalidation Hard?
Cache Invalidation presents a significant challenge in large-scale distributed systems processing high volumes of data. The inherent complexities arise from various factors:
Distributed Systems and Network Latency
In distributed systems, data can be cached across numerous nodes. When the original data is updated, the invalidation signal must reach all the nodes holding the cached copy. This process is inherently susceptible to network latency and potential failures. Sending invalidation messages across a large network takes time, and there's no guarantee that all messages will be delivered on time. This delay can lead to temporary inconsistencies where some users see the updated data. In contrast, others still see the stale version.
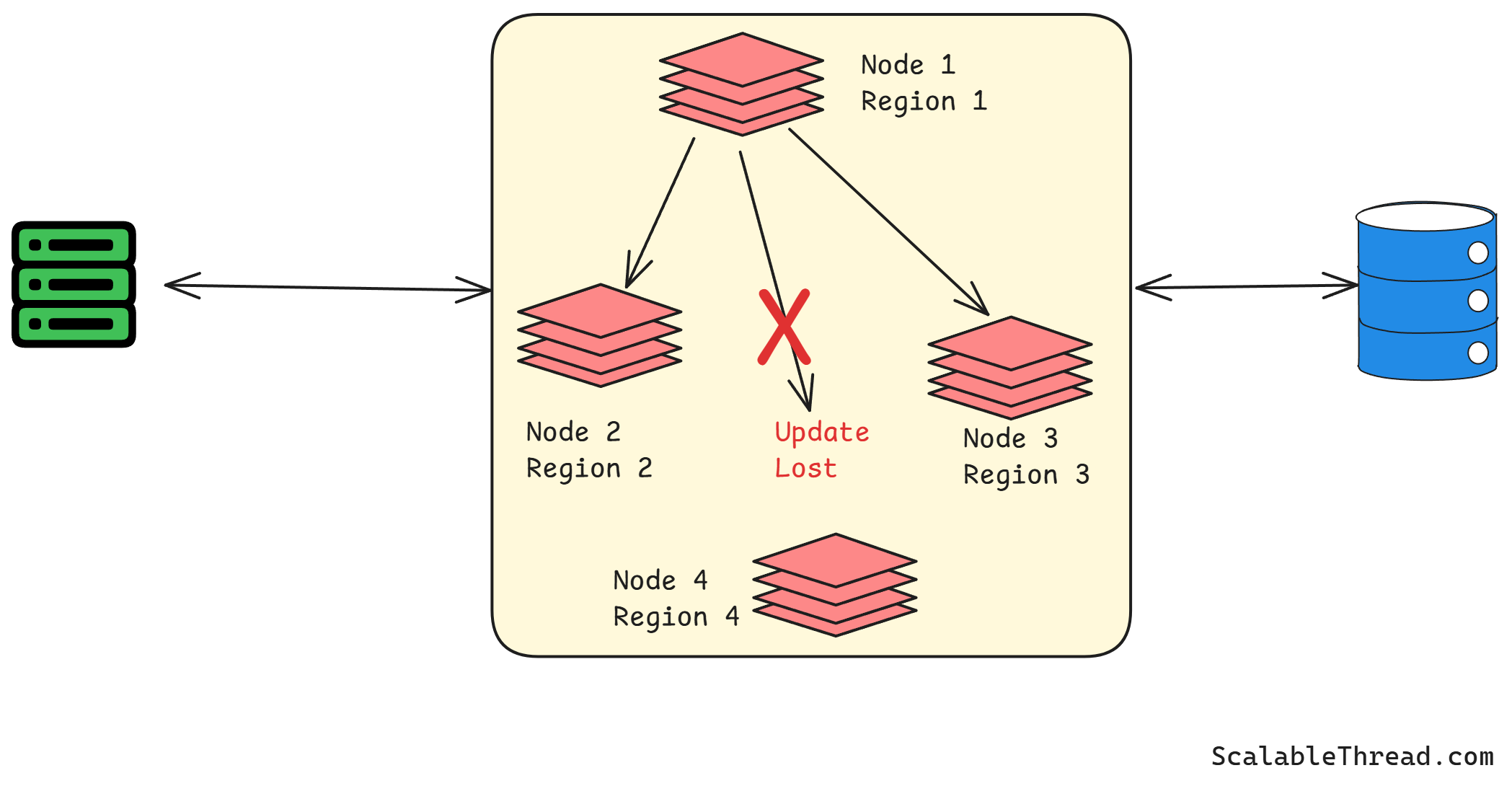
Concurrency and Ordering of Operations
In high-throughput systems, multiple read and write operations can occur concurrently. Ensuring that invalidation messages are processed in the correct order relative to data updates can be challenging. Suppose an invalidation message arrives before the update is fully committed to the primary data store. In that case, the cache might prematurely remove a non-stale entry. On the other hand, the cache will serve stale data if the update is complete before the invalidation.
Balancing Freshness and Performance
There's an inherent trade-off between data freshness and performance. Aggressive invalidation strategies immediately removing cached data upon any update ensure high freshness but can lead to increased load on the primary data store as caches are frequently repopulated. On the other hand, less aggressive strategies that rely on time-based expiration might improve performance by reducing the frequency of invalidation but risk serving stale data for longer periods.
Cache Size Limitations and Eviction Policies
Caches have finite storage capacity. When a cache reaches its limit, it needs to evict some entries to make space for new ones. The eviction policy (e.g., Least Recently Used, Least Frequently Used) can inadvertently remove data that is still valid and might be requested again soon, leading to cache misses and increased load on the primary data store.

False Sharing
False sharing is a performance issue in multi-core processors where two or more data items reside within the same cache line. When one core modifies a data item, the entire cache line is invalidated for other cores, even if they accessed different data items within the same line, which degrades performance. For example, two variables stored contiguously in memory might share a cache line. Updating one variable invalidates the entire line, even if the other remains unchanged.

Resource Constraints and Cost Considerations
Implementing sophisticated cache invalidation mechanisms can be resource-intensive. Maintaining metadata about cached entries, tracking dependencies, and reliably propagating invalidation messages require computational resources, network bandwidth, and storage. The cost of implementing and maintaining these mechanisms must be carefully considered, especially in large-scale systems where even small inefficiencies can have a significant impact.
Predicting Future Access Patterns
An ideal invalidation strategy would proactively invalidate data that is likely to become stale or is unlikely to be accessed again soon. However, accurately predicting future access patterns is a complex problem. Relying on heuristics or historical data might not always be effective in dynamic environments where access patterns can change rapidly. For example, a video streaming service might prefetch content based on user behavior, but unexpected viral trends could render predictions obsolete, flooding caches with irrelevant data.
If you enjoyed this article, please hit the ❤️ like button.
If you think someone else will benefit from this, then please 🔁 share this post.