
How NoSQL Databases Speed-Up Write-Heavy Workloads
Understanding How LSM Trees Optimize Writes in Key-Value Datastores
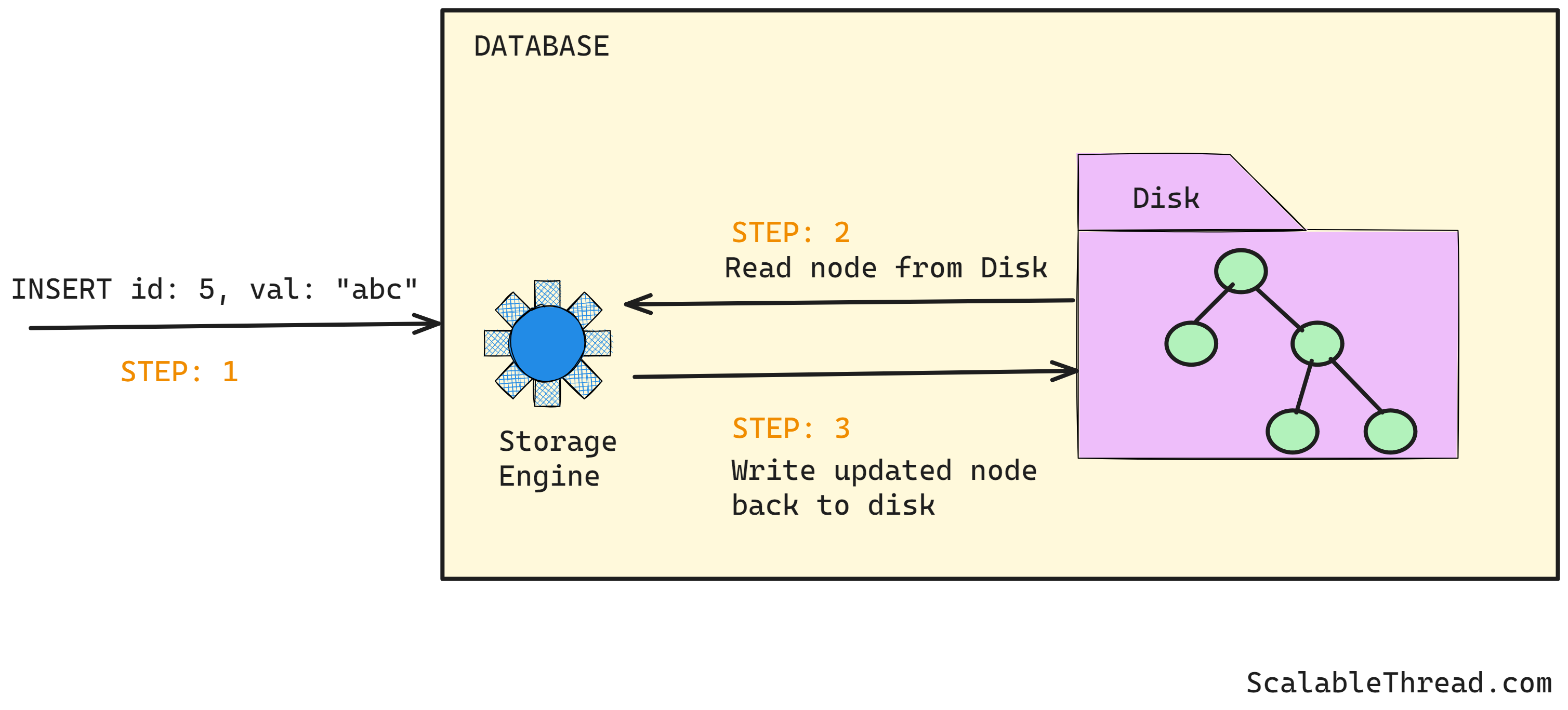
Understanding the Problem
In databases (such as MySQL, PostgreSQL, etc.) that depend on B-trees, writing data requires finding the appropriate tree node (or nodes) to add new data, fetching that node from the disk, making the updates, and writing the node back to the disk. The tree might also need rebalancing in scenarios where a new node is created. In other words, to write a few bytes of data, one or more tree nodes of a few kilobytes each are read from random locations on the disk, updated, and written back. This random disk I/O (which adds to latency) and the high read-to-write ratio (size data read v/s size of new data written) impact the overall write performance.
What is a Log Structured Merge (LSM) Tree?
LSM Tree is a data structure that optimizes the write performance for databases (such as Cassandra, YugabyteDB, etc. ) by buffering the writes in the memory and flushing those writes to the disk at intervals. These writes are flushed to the disk sequentially (sequential disk I/O has lower latency than random disk I/O). An LSM Tree achieves this using two main components:
1) Memtable
Memtable is an in-memory data structure (like AVL trees) that keeps the key-value pairs of data sorted by the key. Compared to B-Trees, which keep the data sorted on the disk (random disk I/O), keeping data sorted in an in-memory memtable is faster. This allows for faster write and read operations to the sorted memtable. All the writes are first written to the in-memoy sorted memtable, which is then flushed to the disk once the memtable is full.
2) Sorted String Tables (SSTables)
Once full, the memtable is flushed to Sorted String Tables (SSTables), append-only (no updates allowed) files stored on the disk. Data on SSTables is sorted by the key, and for the same key, values later in the file are newer than the values earlier in the file.

Understanding Compaction in SSTables
When a memtable is full, it’s written to the disk as an SSTable file sorted by the key. Multiple memtable flushes result in multiple SSTable files. Over time, the same key can end up in different SSTable files because a key in a database can be updated with different values at various times, and SSTables are append-only. This means that the most recent memtable flush will have the current value for a given key compared to an earlier memtable flush.
To keep the data updated with the most recent values, SSTables run a merge and compaction process from time to time, during which multiple SSTable files are merged into one. This process runs as follows:
The first entry is read from the top of each SSTable file, and the keys are compared
The key-value pair with the smallest key is added to the new SSTable file. If all the files have the same key with different values, then the most recent file’s key is considered (as that will have the most recent update); the rest are discarded.
The process is repeated until key-value pairs from all files are moved to the new merged and compacted file.

Fig. Merge and Compaction in SSTables

Writes in LSM Trees
The write is first written to the memtable (keeps the data sorted by key)
Once the memtable is full, it is written on the disk as an SSTable file. The data is written in a sorted and append-only way (sequentially) to SSTable. This doesn’t impact performance as the memtable already holds the data in sorted order. This allows LSM trees to support high write throughput.
At intervals, different SSTables files are merged and compacted.

Fig. Writes in LSM Trees

What Happens to Memtable Data in Case of a Crash?
Since memtable is held in memory, a database crash can lead to the loss of this data. To address this concern, the data in the memtable is also written in the Write-Ahead Logs (WAL Logs). If a crash happens, the memtable is reconstructed from WAL logs, and once the memtable is flushed to the disk, its corresponding WAL logs are discarded.

Reads in LSM Trees
The key to be read is first searched in the memtable. Since it is in memory, the lookups are quick.
If the key is not found in the memtable, it’s looked in the most recently flushed SSTable file. If not found, then in the next-older SSTable file, and so on. This is because the reads can happen before all SSTables files have been merged and compacted into one file.

Fig. Reads in LSM Trees

How are Reads Optimized?
Scanning SSTable files can impact the read performance. To optimize reads:
Bloom Filters are often used to determine if a key exists in SSTables or not
An in-memory index is created for some of the keys (sparse index) in the SSTables. This index holds a few keys mapped to their location in an SSTable file. Any key read is first looked up in this sparse index, and the locations of the keys before and after the given key are found. Since the data in SSTables is sorted, the given key will be somewhere between these two locations. This speeds up reads as only the keys between the two locations must be scanned to find the given key. This is similar to finding a word in a dictionary, where instead of scanning the whole dictionary word by word, we look up the list between the two words, one of which is before the given word and another after it

Fig. Optimizing reads in LSM Tree using Sparse Index

References
Wikipedia contributors. (2024b, September 13). B-Tree. Wikipedia. https://en.wikipedia.org/wiki/B-tree#B-tree_usage_in_databases
Kleppmann, M. (2017, Chapter 3). Designing Data-Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems. “O’Reilly Media, Inc.”
Sadeghi, Y. (2024, February 7). What is a Log Structured Merge Tree? Definition & FAQs | ScyllaDB. ScyllaDB. https://www.scylladb.com/glossary/log-structured-merge-tree/
Log structured merge(LSM) tree and Sorted string table (SST). (2024, April 22). YugabyteDB Docs. https://docs.yugabyte.com/preview/architecture/docdb/lsm-sst/