
How to Improve Performance of Your Database?
Strategies for Scaling Databases in Distributed Systems
Scaling a database is critical for systems handling massive data volumes and high traffic. Scaling becomes necessary for several primary reasons. First, performance degrades as data volume and concurrent user requests increase. Queries that were once fast can become slow, leading to a poor user experience. Second, applications require high availability.
Strategies
Several techniques can be employed, often in combination, to scale a database.
Indexing
Indexes speed up data retrieval by creating pointers to rows, similar to a book's index. Instead of scanning an entire table (full table scan) to find specific rows, the database can use an index to locate the data quickly. For example, consider a orders table with millions of rows. Searching for an order by the order_id without an index would require scanning every row. Creating an index on the order_id column allows the database to find the user's record almost instantly.
Trade-off
Indexes speed up read queries (SELECT) but slow down write operations (INSERT, UPDATE, DELETE) because the index must also be updated during writes. They also consume disk space. Choose indexes wisely based on common query patterns.

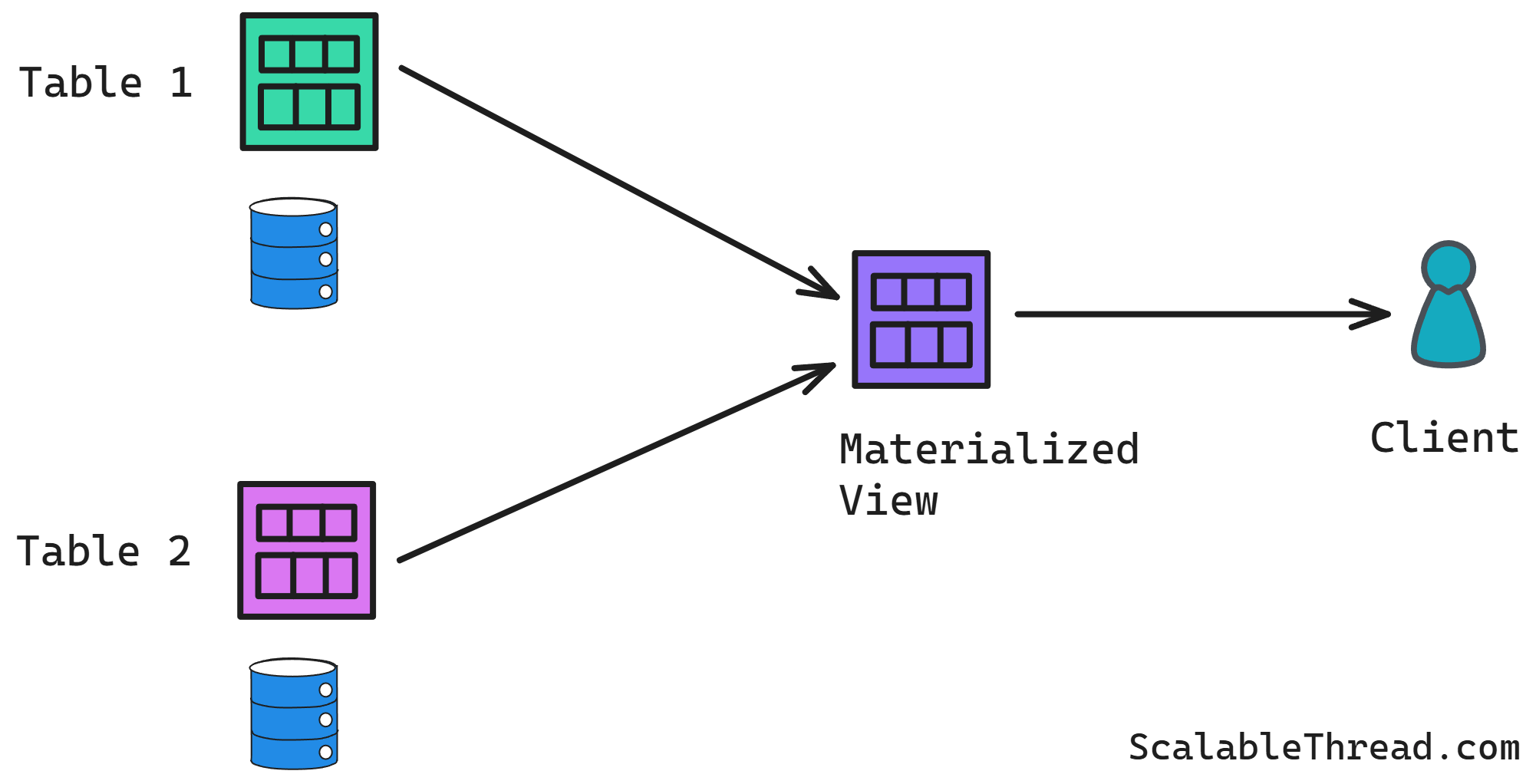
Materialized Views
Materialized views store the pre-computed result of a query. For complex queries involving joins or aggregations that run frequently, computing the result once and storing it can reduce query time. For example, an analytics dashboard displays daily total sales aggregated by product category. This query involves joining orders, order_items, and products tables and performing aggregations. Creating a materialized view, daily_sales_by_category, that stores these daily totals allows the dashboard to load much faster by querying this simple view.
Trade-off
The data in a materialized view can become stale. It needs a refresh strategy that consumes resources (e.g., nightly or triggered by data changes). Materialized views also consume storage space.
Denormalization
Normalization is organizing database tables to reduce data redundancy and improve data integrity, often involving splitting data into multiple related tables. Denormalization is the opposite process: intentionally adding redundant data to one or more tables to avoid costly joins when querying. For example, an e-commerce application must frequently display the product name and order details. A normalized design might require joining the orders table with the products table. To speed this up, you could denormalize by adding a product_name column directly to the orders table. This avoids the join during reads.
Trade-off
Denormalization increases storage requirements. More importantly, it complicates data updates and increases the risk of data inconsistency. If a product name changes, it must be updated in every order record referencing it, not just in the central products table.
Vertical Scaling
This involves increasing the resources of the existing database server, such as adding more CPU power, RAM, or faster disk storage (like SSDs).
Trade-off
Physical limits exist to how much you can scale up a single machine. High-end hardware is expensive. It does not significantly improve fault tolerance, as you still have a single point of failure. Upgrades often require downtime.

Database Caching
Caching involves storing frequently accessed data in a temporary, fast-access memory layer (like Redis or Memcached) between the application and the database. Subsequent requests for the same data can be served directly from the cache, bypassing the database entirely. For example, a news website caches popular articles. When a user requests an article, the application first checks the cache. If the article is cached, it's returned immediately. If not, the application queries the database, returns the article to the user, and stores a copy in the cache for future requests.
Trade-off
Cache invalidation is a complex problem. Caching adds another component to manage and introduces potential consistency issues (stale data). It primarily helps with read-heavy workloads.

Replication
Replication involves creating one or more copies (replicas) of the primary database server. Write operations (INSERT, UPDATE, DELETE) to the primary server. Read operations (SELECT) can be distributed across the replicas. This distributes the read load and improves read throughput. Replication also provides high availability; if the primary fails, a replica can be promoted to the new primary.
Trade-off
There is often a replication lag before changes on the primary appear on the replicas. This can lead to reading slightly stale data. It increases infrastructure costs and complexity. It does not solve bottlenecks related to high write volumes on the primary server.
Sharding
Sharding involves partitioning the database data horizontally across multiple independent database servers, called shards. Each shard contains a subset of the total data. The application logic or a proxy layer routes queries to the appropriate shard based on a partition key. This distributes both read and write loads across many machines.
Trade-off
Sharding increases complexity in both application development and database operations. Queries that need data from multiple shards become complex and slow. Rebalancing data is challenging. Choosing an appropriate shard key is critical to avoid uneven data distribution.

When to Consider?
Scaling introduces complexity and cost, so it should not be implemented prematurely. Start monitoring key database metrics early. Before implementing complex scaling solutions, always investigate if query optimization or schema improvements can resolve the bottlenecks. Rewriting inefficient queries or adding appropriate indexes sometimes provides relief without infrastructural changes.
If you enjoyed this article, please hit the ❤️ like button.
If you think someone else will benefit from this, then please 🔁 share this post.